高价的射频和 FPGA 硬件,贵的能顶一辆车,却大多数时间都在闲置。一个实验室或一个团队,买来一台 软件无线电或一块 FPGA 板卡,跑几次采集,板卡就上了架。这些硬件远不止收发那么简单,挡住它的, 是在上面做真正的定制开发,确实很难。
这个博客里的其他文章,本身就是反例:一个在巴掌大的电台上生成并跑通的 Wi-Fi 接收机,一颗时钟 越过商用器件的译码器,一条流程里出来的二十个译码器。这篇,讲的是它们背后那个”为什么”。
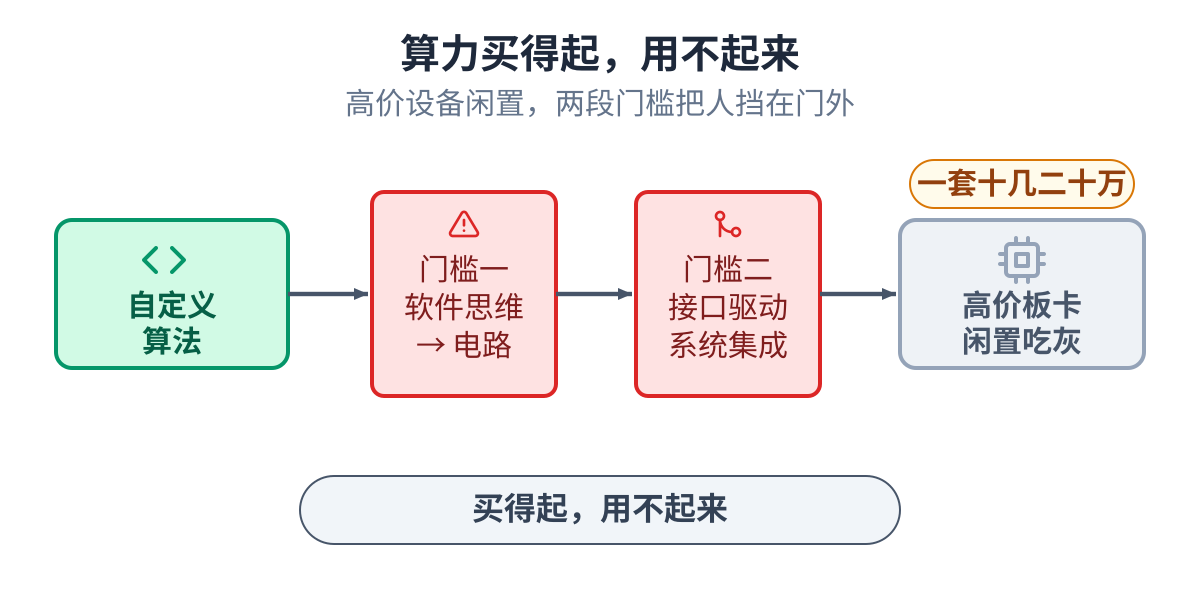
算力买得起,却用不起来
门槛分两段,一个项目两段都得迈过去。
第一段,是把软件算法变成高效的硬件。处理器一条接一条地执行指令;芯片的逻辑在同一个时钟节拍里 跑成百上千个运算。同一个算法,写成能跑,和写成又快又省,是两个不同的设计,两者之间的距离是一 门专门的手艺。
第二段,是让这套硬件真正在板子上跑起来:接口、数据搬运、驱动,以及外面那层软件。这需要一个既 懂底层逻辑、又懂上层软件的人,一旦出问题,还很难判断是哪一层坏了。
这两段门槛叠在一起,让昂贵的硬件用不充分,也让愿意学这门手艺的人越来越少。
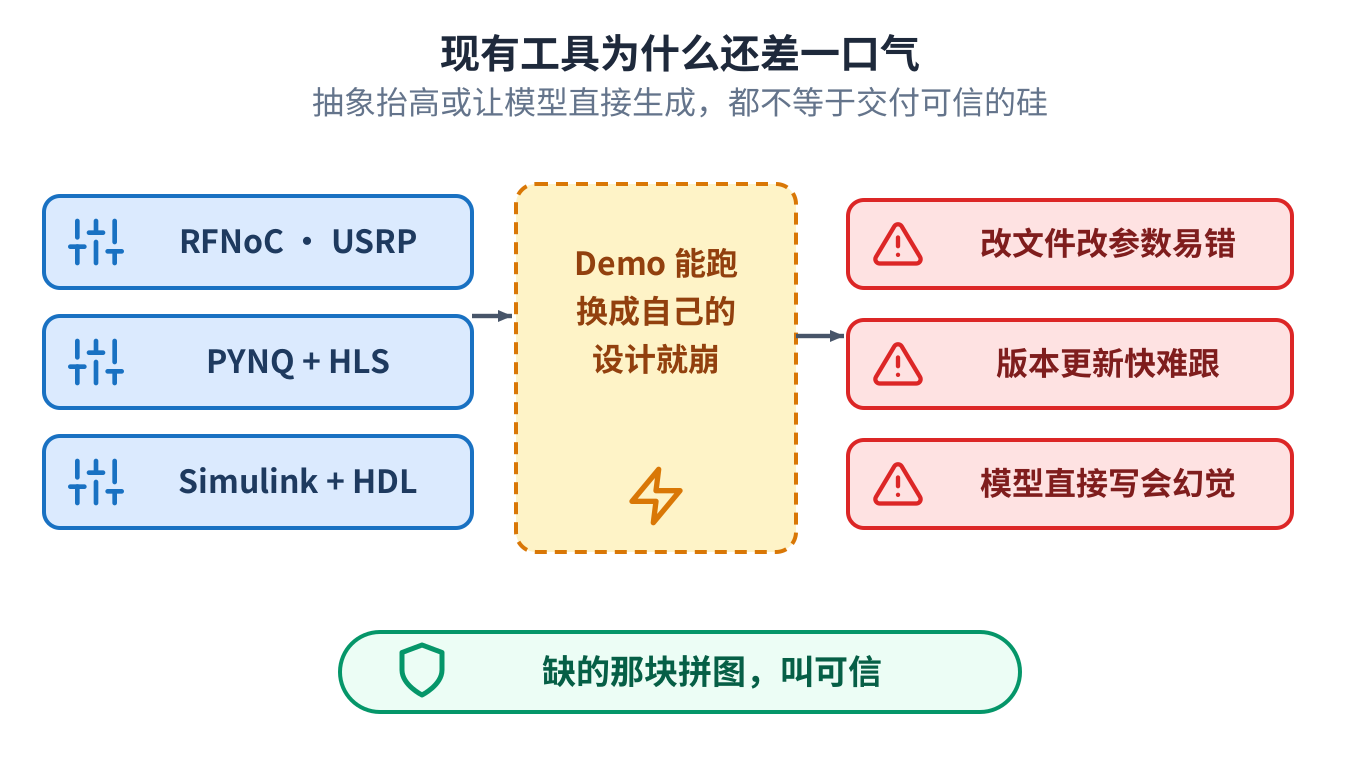
现有的工具为什么还差一口气
厂商做了不少工具来降低门槛,它们有帮助。可共同的体验还是一样:Demo 能跑,一旦把你自己的设计 放进去,问题就冒出来。整个流程要大量手动修改,工具还更新得快。
把抽象层抬高,本身并不能填平这道沟。那些把类 C 代码变成硬件的高层次工具,和手写逻辑之间还有 一道实打实的速度差距,而且要从里面拿到好结果,仍然需要很深的硬件经验。
更新的一个想法,是直接让大语言模型写硬件,它有个绕不过去的问题:模型生成的硬件看着合理,功能 却是错的。在标准的评测上,最好的方法把功能正确率推到了接近九成,剩下的那部分仍然是错的,没有 一种方法能把它彻底消除。缺的那块,是可信。
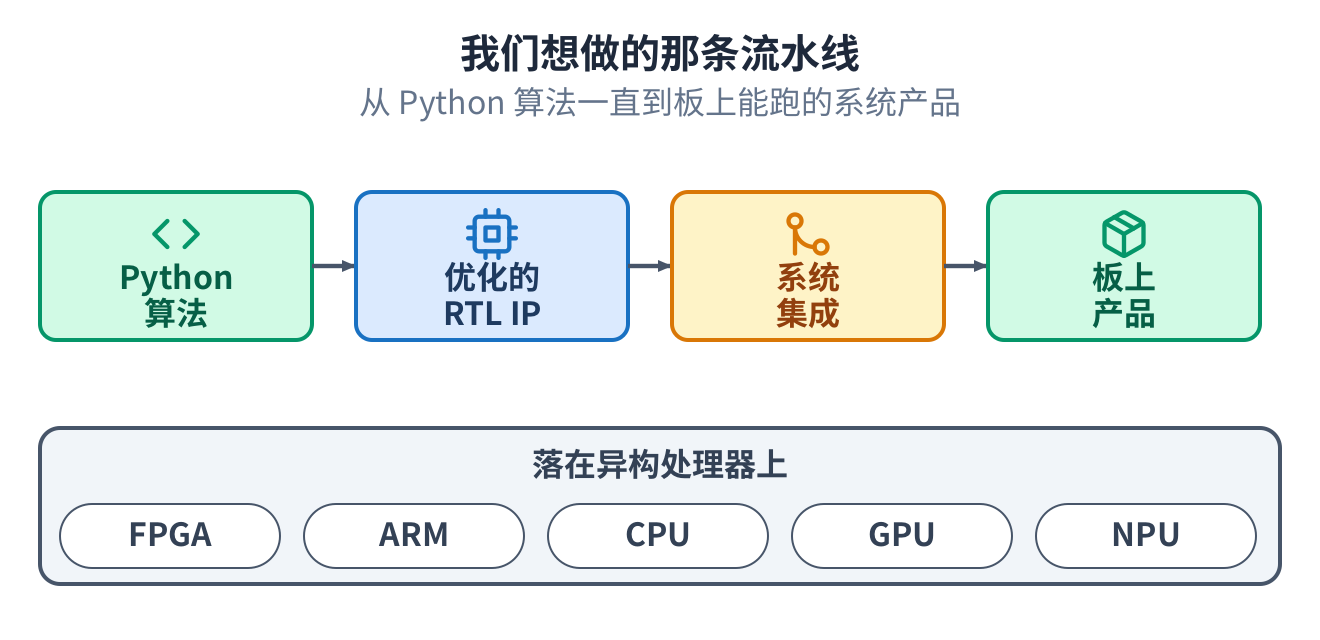
一条流程,从算法到能跑的产品
我们做的,是一条自动化流程,把一个 Python 算法,经过优化的硬件,做成在真实设备上整系统集成、 能运行的产品。不只是 FPGA 逻辑:同一条流程也把工作分配到主机处理器、嵌入式核,以及旁边的加速 器上,让它们一起干。
这条流程从算法生成优化好的硬件,完成时序收敛、把资源用到最省,这些都是没人爱做的部分,再把设 计搬上板:集成、上板前后的仿真,以及板上测试。串起来,就是一条从算法到能跑的东西的路。算法在 最前面,能跑的系统在最后面,中间又难又琐碎的部分,被自动化掉了。
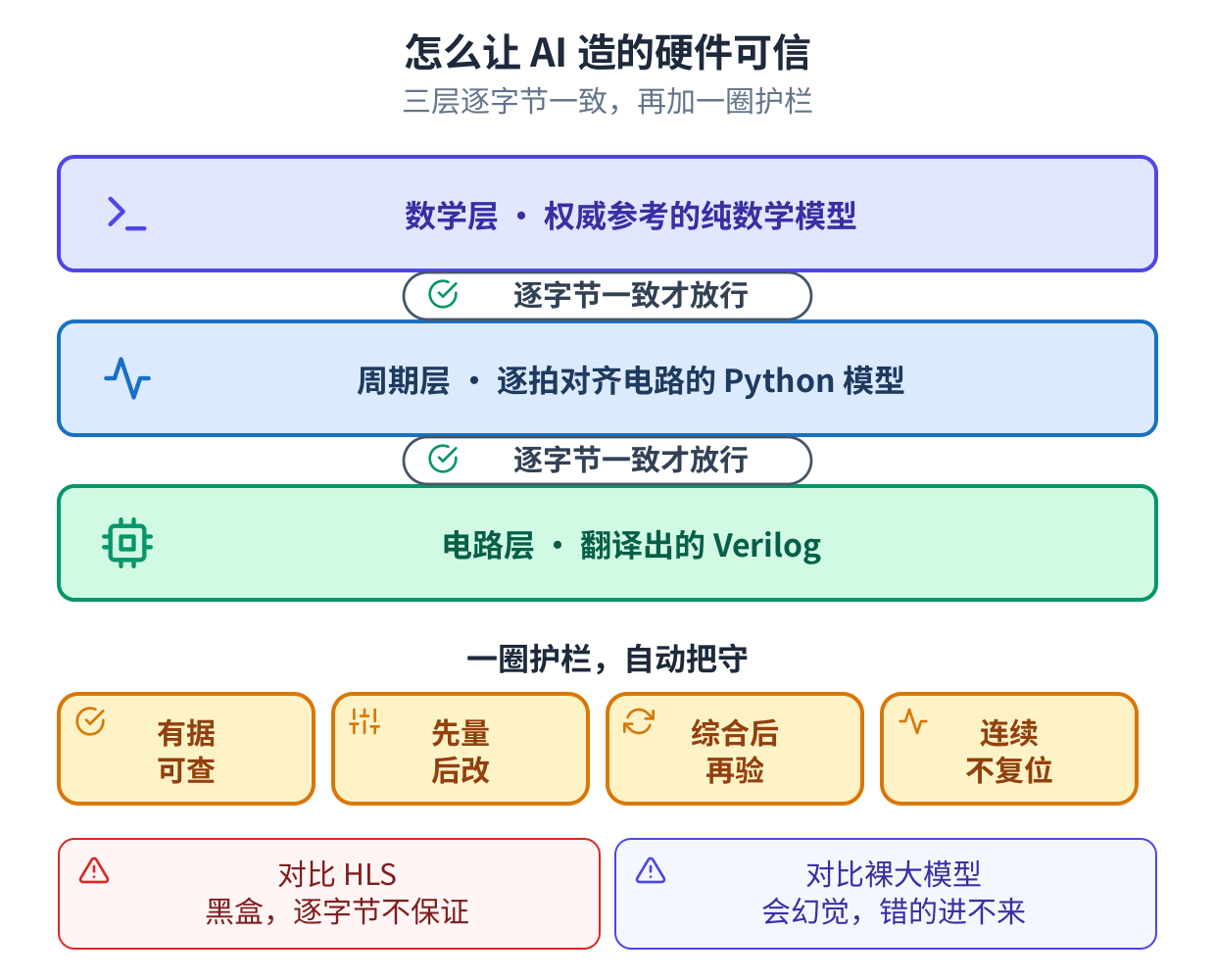
最难的是可信
让机器写硬件不难,难的是让它写出你能信得过的硬件。办法是一条由三个模型组成的链子,每一个都是 下一个的基准,外加一组自动护栏。
这三个是:一个数学模型、一个时钟精确模型,和硬件本身。数学模型对照权威标准核对,是对错的裁判。 时钟精确模型逐拍跟着硬件走。硬件从它生成,再对它逐比特核对,做核对的测试用例由数学模型生成, 从不手写。三个模型逐比特一致,否则不放行。
链子之外是一圈自动检查把守的护栏:任何数字都要能追到一份真实的工具报告,没量过就不改,连续工 作的设计要背靠背、中间不复位地测。关于这一层,我在另一篇讲 Wi-Fi 接收机如何逐层验证正确的文章 里写得更细。一句话说,可信的机器硬件,来自每一步都对一个独立基准核对到比特,与模型聪明与否无关。
它不是承诺,是已经验证过的
这套方法不是一个计划,它已经在真实的硅上跑着。
一个完整的 Wi-Fi 接收机,跑在一台巴掌大的电台上,把标准里全部八种模式都在空口上一比特不差地收 了回来;因为它太大装不进那颗小芯片,于是拆到了电台的逻辑和一台笔记本上。一颗 5G 纠错译码器,从 Python 描述生成,时钟被优化到越过同一颗芯片上的付费商用器件。二十个译码器配置,从一条流程里出 来,每一个都对照标准核对过。这些,都在这个博客里用平实的话写过。
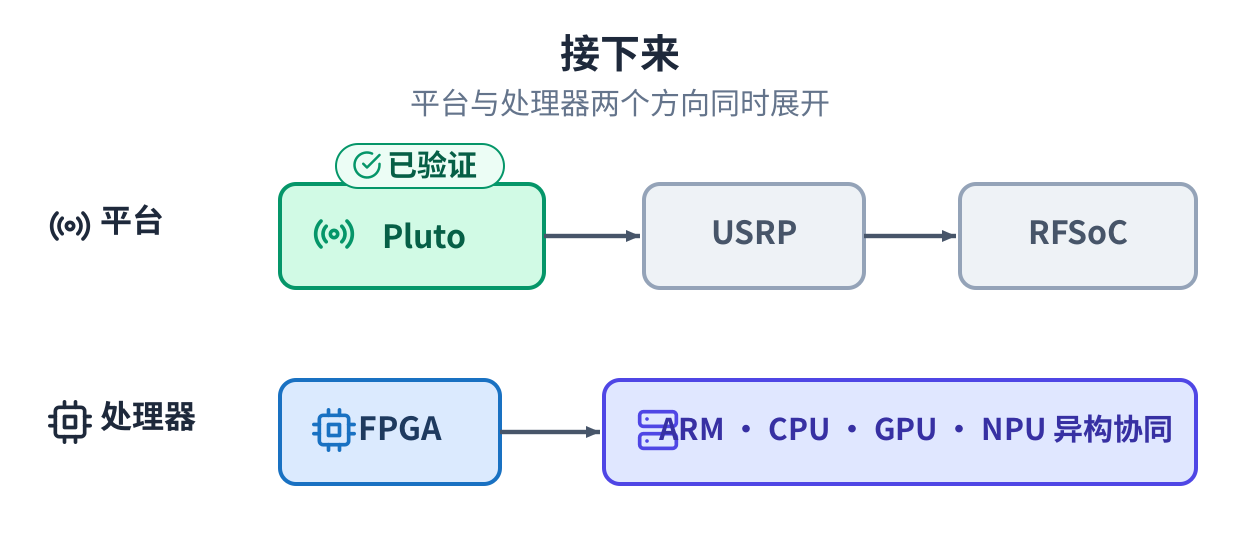
接下来
两个方向。一个是平台:从巴掌大的电台,推到更大的软件无线电和射频片上系统板卡。另一个是处理器: 从 FPGA,延伸到 CPU、嵌入式核,以及加速器协同。目标自始至终是一个:把从算法到芯片这条路,变成 一条你能信得过的自动化流程,让人们已经买下的算力被真正用起来,而不是搁在架子上。
我们多数人都有一块搁在架子上的板卡,和一个躺在文件里的算法,还有一种隐隐的感觉:把这两者接起 来,代价大过它的价值。如果代价没那么大了呢?
注
- 这篇文章背后的那些案例,Wi-Fi 接收机、LDPC 译码器、维特比折叠,都在博客首页。
- Wi-Fi 接收机的空口实时演示,在浏览器里回放真实采集的数据:algosilicon.com/assets/demos/wlan-pluto-rx。
- 这里的少数几个证据点,是那些文章里实测结果的定性概括。