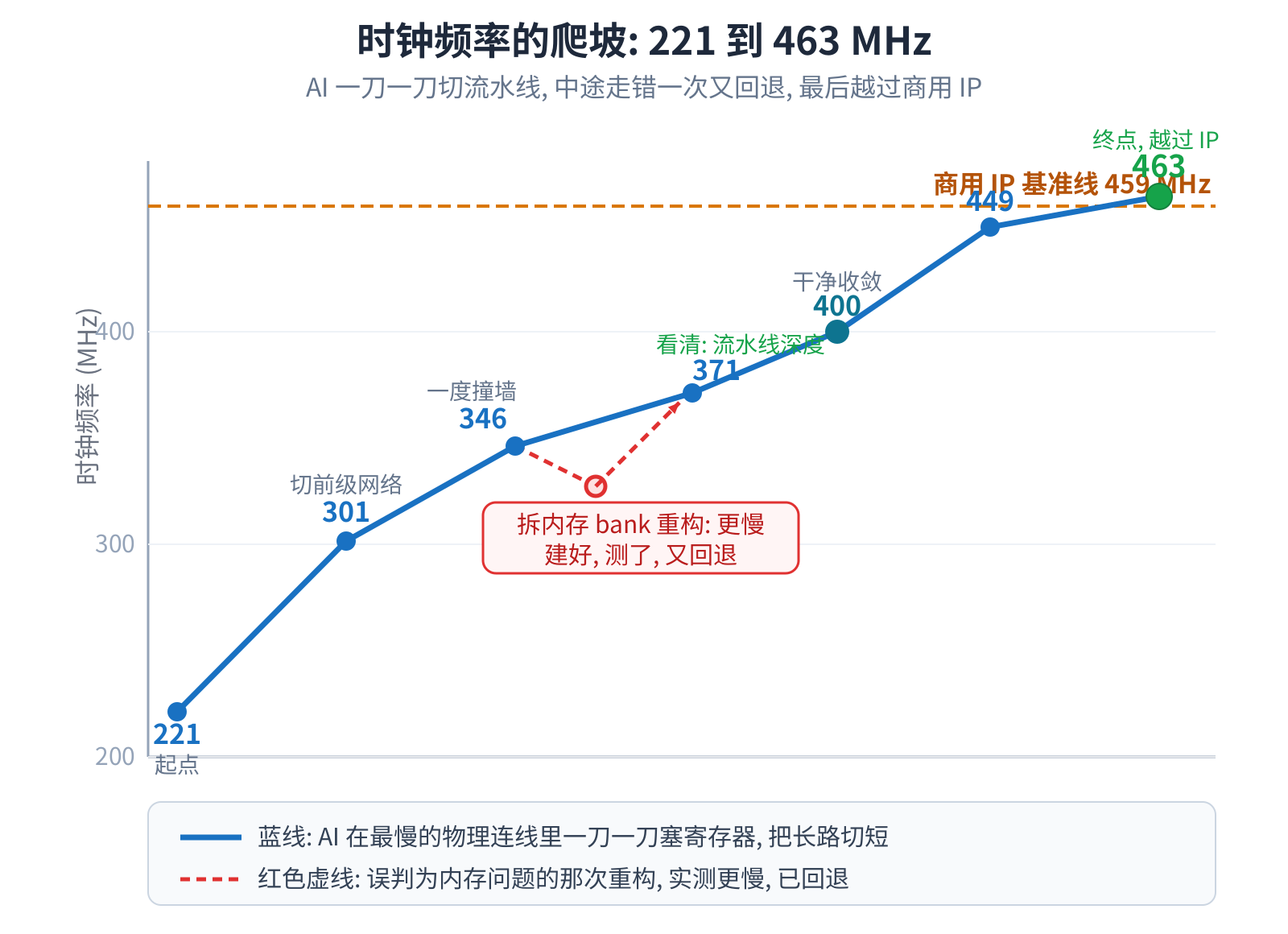
让大模型写几行代码早就不稀奇了。难的是另一件事:在真实的物理约束下,把一个 RTL 设计往死里优化,还不能算错 一个比特。这篇讲一个完整的案例:一颗 5G LDPC 译码器,Verilog 由我的 Python2Verilog 框架从 Python 算法 自动生成,再交给 AI 抠时序。起点 221 MHz,中途撞过墙、还走错过一次路,最后做到 463 MHz,越过同一颗 FPGA 上付费商用 IP 的 459 MHz。
有意思的不是 AI 写了代码,而是它能在物理约束下分清方向、敢于回退,还能啃下那块绕不过去的硬骨头:LDPC 译码里层与层之间的数据依赖。这才是它开始像个工程师的地方。
拉高时钟,为什么没那么简单
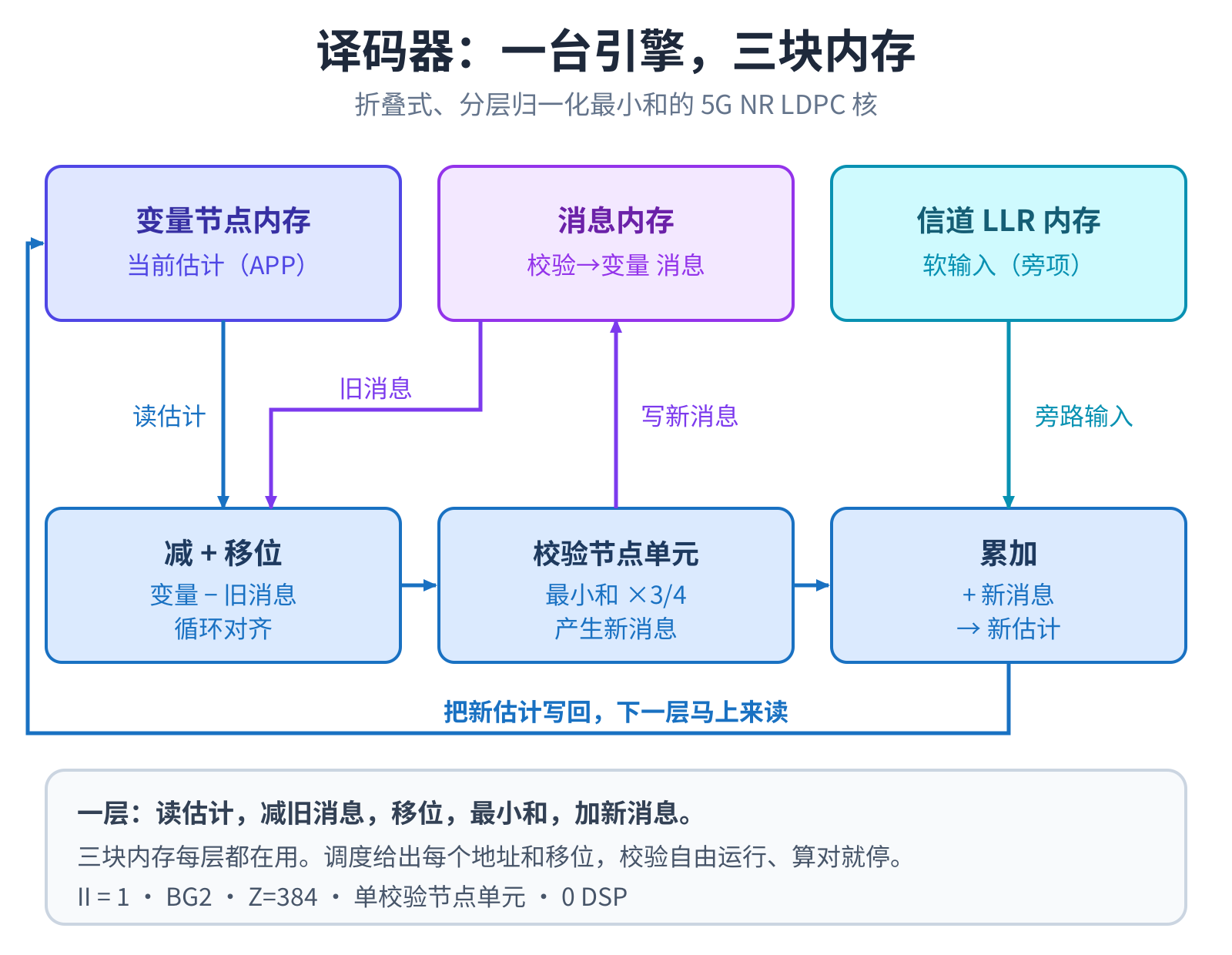
在 FPGA 上,这颗译码器是一个循环:读出每个比特的当前估计,减掉旧消息、做循环移位,校验节点单元算出新消息, 再把新消息连同信道软信息累加、写回。变量估计、消息、信道是三块各自独立的内存,每层都在用,一层接一层地迭代, 算自洽了就提前停。
频率越高,单位时间处理的数据越多,所以拉高时钟是最核心的目标之一。可它不是想多高就多高:每过一拍,信号得在 一个时钟周期内,从一个寄存器出发,穿过几层逻辑,再走过一段实实在在的物理连线,赶到下一个寄存器。只要有一条 这样的路走不完,整颗芯片的时钟就被这条关键路径拖住。而现代 FPGA 上,最慢的路往往是布线主导的,不是逻辑:到了 终点这条最慢路总共约 2.1 ns,真正算东西的逻辑只占一小截,约七成时间全耗在布线上。
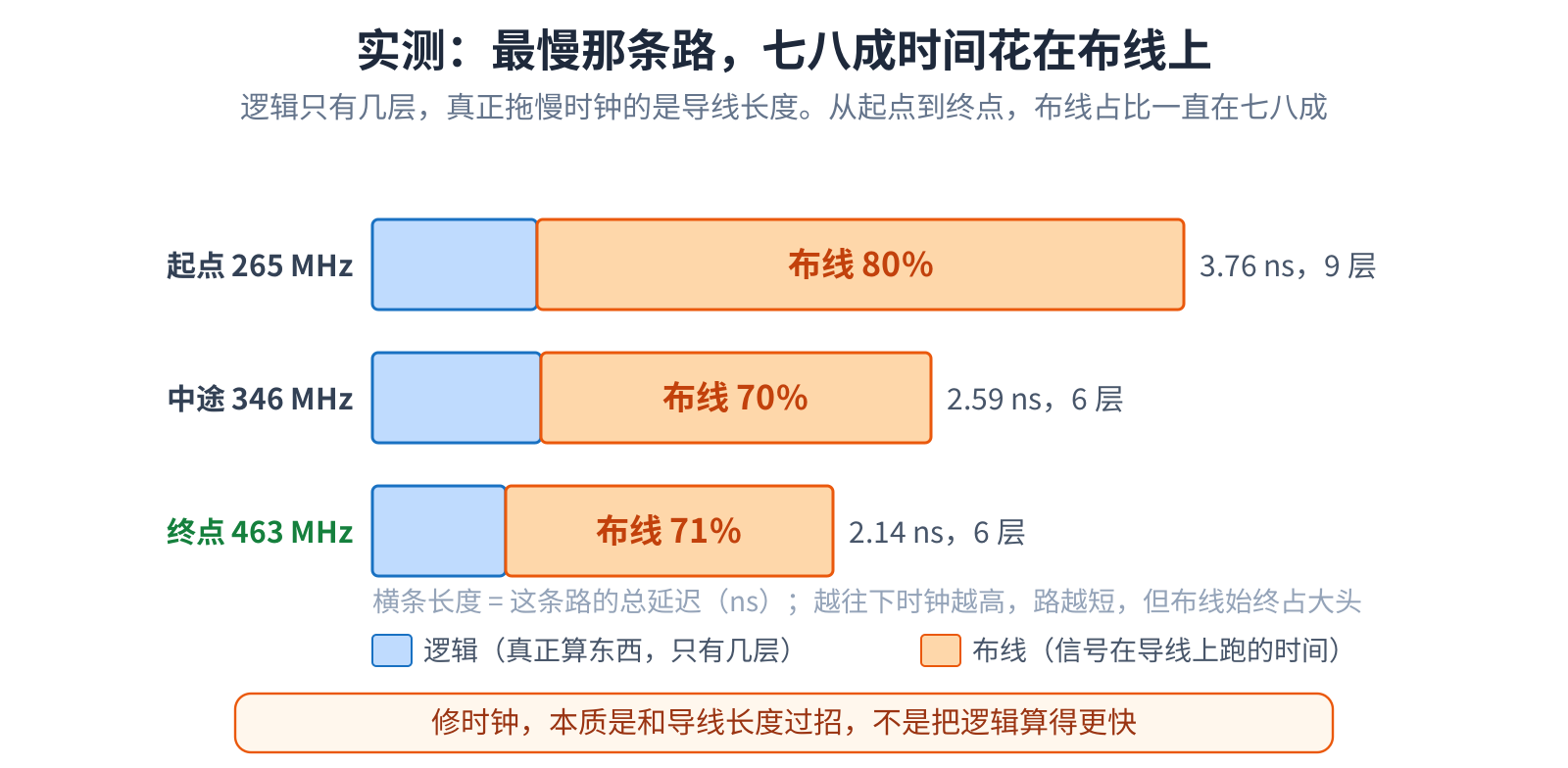
一条慢路到底卡在”算得慢”还是”走得远”,决定了你该用哪种办法去修。长线最直接的修法,是在它中间插一级寄存器, 把一长段拆成两短段,每段都在一拍内走完。寄存器必须落在长线的中间,插在两端是白费的。
真正的硬骨头:层与层之间的依赖
把变量内存想成一块共享的草稿本,记着每个比特此刻的最佳猜测。每一层读它、算一轮校验、写回,紧接着下一层马上又 来读这块刚改过的草稿本。这个”先写后读”的依赖,正是这里插寄存器会出事的原因:寄存器把更新推迟一拍,下一层却按 原节奏读了过去,读到旧值,译码直接发散。
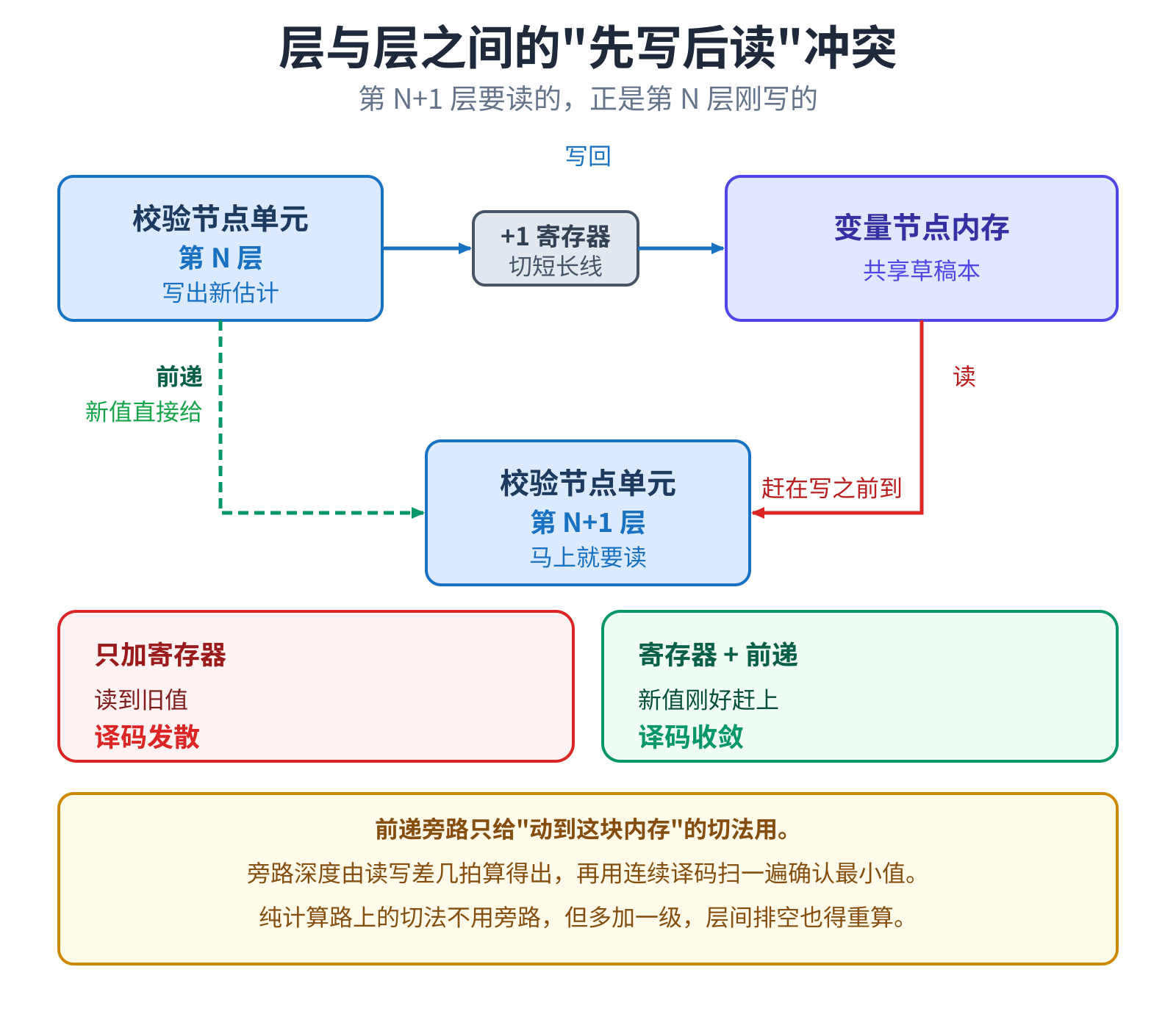
它还有点隐蔽:第一帧测试经常是绿的,因为草稿本初始全是 0、旧值恰好也是 0;一连续译码,残留就把它顶穿。所以 只要这一刀动到了共享内存,就得同时拉一条前递旁路,深度卡到”刚好不发散”的最小值。
走错的一步:以为问题出在内存
撞墙之后,AI 起了个念头:是不是这颗译码器的内存结构本身就是天花板了?于是它给了个挺有野心的方案,把大内存拆成 多个小块,让计算和内存就近配对。这方案不是嘴上说说,是真的实现了、综合了、布局布线测了。结果是一盆冷水:拆完 非但没提速,反而因为多出来的寻址和边界逻辑,把时钟拖低了,方案回退。
值钱的是回退之后的复盘。AI 回头读那条最慢路径的真实报告,发现它压根不是一条”内存寻址”的路,而是一条”计算 + 取数”的路,早就紧凑地摆在芯片一角了。问题从来不在内存怎么摆,而在这条计算路流水线不够深。
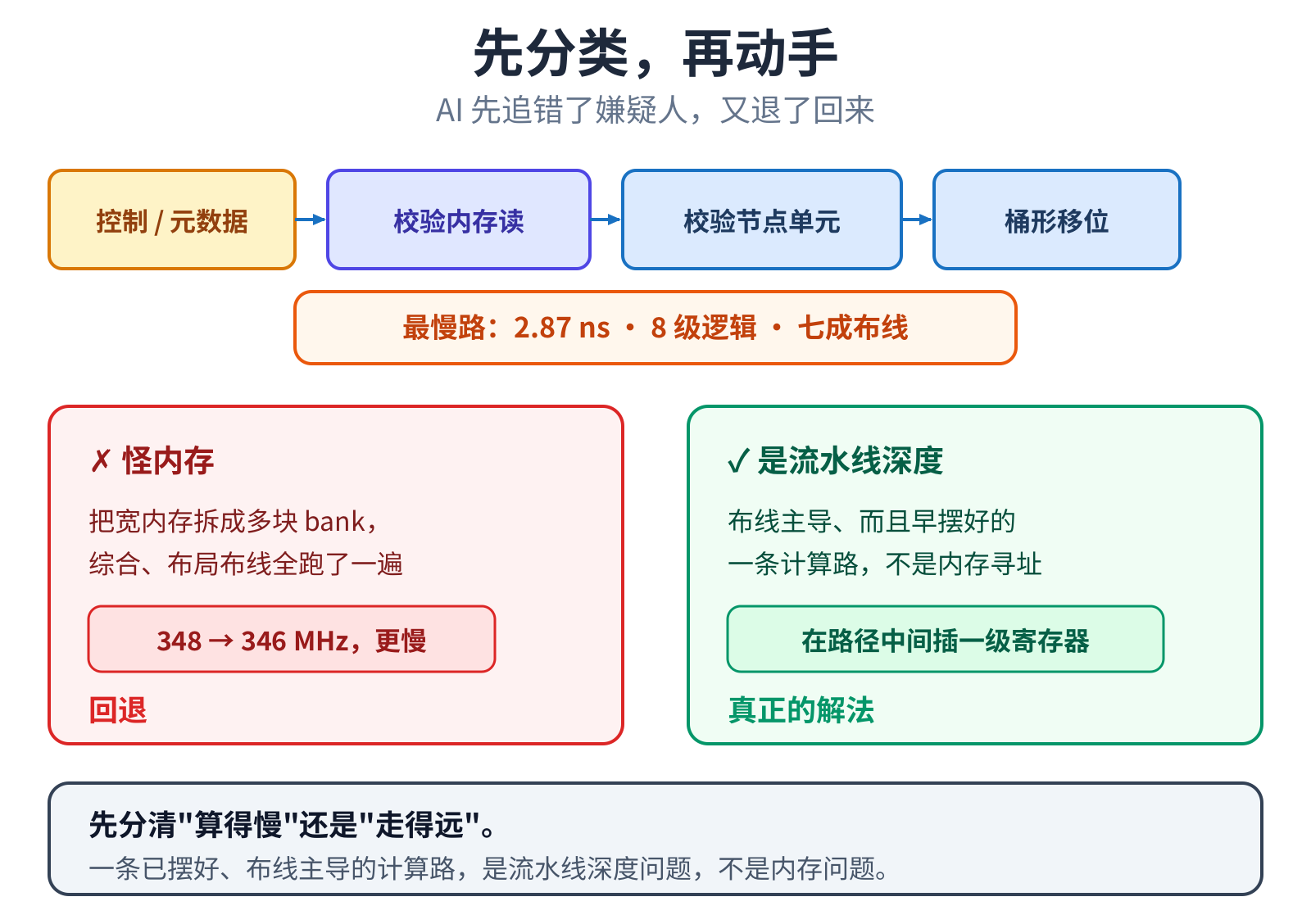
这是最贵也最值钱的一课:动手重构一个大模块之前,先把当前最慢那条路拉出来,分清它卡在”算得慢”还是”走得远”。 在错的诊断上使劲,越使越糟。
六刀连切,越过 459 MHz
认清”这是流水线深度问题”,路一下就通了。AI 回到最朴素的办法:在最慢的几条”计算 + 取数”长路中间插寄存器、把 它们切短,动到内存的那几刀都配好前递旁路,这回切得更准。几个代表手法:寄存内存的读出口,不动读取时序就把后面 那段长路切短;寄存内存的写入级,让数据多一拍走到内存;把已有的中点挪个位置,不新增一级、零延迟白赚时钟。六刀 连切,时钟从三百多冲到 463 MHz,中途干净收敛,最后越过商用 IP 的 459。
两个小插曲:一是”拥塞”的错觉,翻开报告根本没拥塞,就几条差不多长的路一起卡着。二是反直觉的”过约束”,一般经验里 目标定太高工具会摆烂,可这个设计摆放有余量,目标定得更紧反而逼出更好的结果。规则都有适用条件,照搬会翻车。
那吞吐量呢?基本打平
说句实在话,吞吐量我没赢。两边架构相近,跑下来基本打平,顶多因为时钟略高而稍稍靠前。这个码率下两边都只跑真正 有用的那几层,早停也都是业内通行做法。这篇真正站得住的胜利只有一个:时钟。
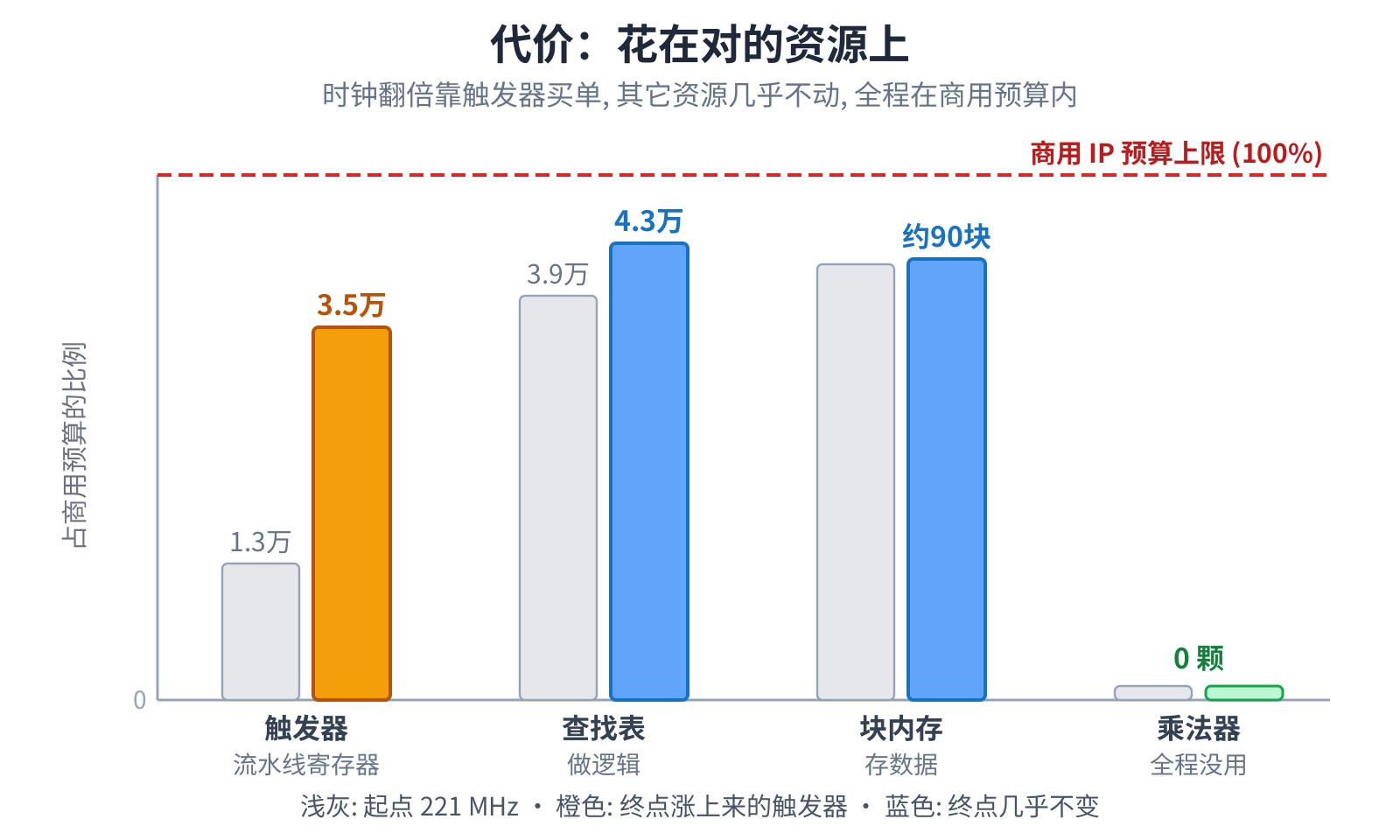
代价:花在了最便宜的资源上
时钟翻倍总要付代价,关键是付在哪种资源上。前面一刀刀塞进去的寄存器和旁路,花的几乎全是触发器,而查找表和块内存 几乎没动,乘法器全程是 0。而且不管怎么翻,所有资源始终没出商用 IP 的预算框。触发器本就是 FPGA 上最便宜、最不缺 的资源,把代价花在它身上,是笔划算买卖。
每一刀都对得上官方参考
速度再快,算错就一文不值。所以整条路有一条铁律:每改一刀,都用仿真把硬件输出和算法基准逐比特对照,一个比特都 不能差。最后这颗译码器还跟 MATLAB 5G 工具箱里的 3GPP 官方实现做了交叉验证:编码部分多组随机测试逐比特一致, 译码部分在多种信道配置下与官方实现完全一致。

我带走的几条判断
比数字更值得带走的,是这条路上反复印证的几条判断。先分类再动手:一条慢路,先分清”算得慢”还是”走得远”,在错的 诊断上使劲只会越使越糟。别怕承认走错:内存重构那步,建好、测了、更慢、回退,干脆接受一个负面结果本身就是工程 能力。最难的那块,往往是绕不过去的依赖。比的时候要诚实:时钟是真赢了,吞吐其实打平,能这么说,才对得起读者。
你有没有过这种经历:认定瓶颈在某处,折腾半天,最后发现压根看错了地方?