上一篇里,我用 AI 把一颗 5G LDPC 译码器从 221 优化到 463 MHz,在同一颗 FPGA 上越过付费商用 IP。那只是一种配置。5G LDPC 标准支持 两张基矩阵和 51 种提升因子,组合起来有很多码点。要证明这套时序方法具有通用性,就得用同样的方式做出更多译码器。
手调一颗译码器,算不上一套设计方法。AI 在这里真正的价值,不是调好某一个设计,而是把这个过程自动化:批量地、 快速地,把各种配置下的设计都调好,并且逐个证明它对。
调好一个只是起点,工具才是目标
5G LDPC 标准的每一种码点,都对应一套不一样的 FPGA 电路。配置一变,资源和时序优化就得从头再来。与其每种配置都 盯着调,不如把那套时序方法提炼成一条自动流程:靠参数化,把二十种配置下的译码器自己生成出来,逐个完成时序收敛和 正确性验证。这二十种覆盖了两张基矩阵、各两类码率、五种提升因子,信息位长度从几百到几千比特不等。
同一副骨架,换参数生成
这是关键:这二十个译码器,不是手写二十遍,而是同一个生成器换参数生成的。骨架还是上一篇那颗折叠式分层译码器—— 读估计、算校验、累加写回。所谓”折叠”,就是不把一层的几百个通道一股脑全铺开,而是分成几趟、每拍算一批,硬件省 一大圈,还是单引擎、零 DSP。
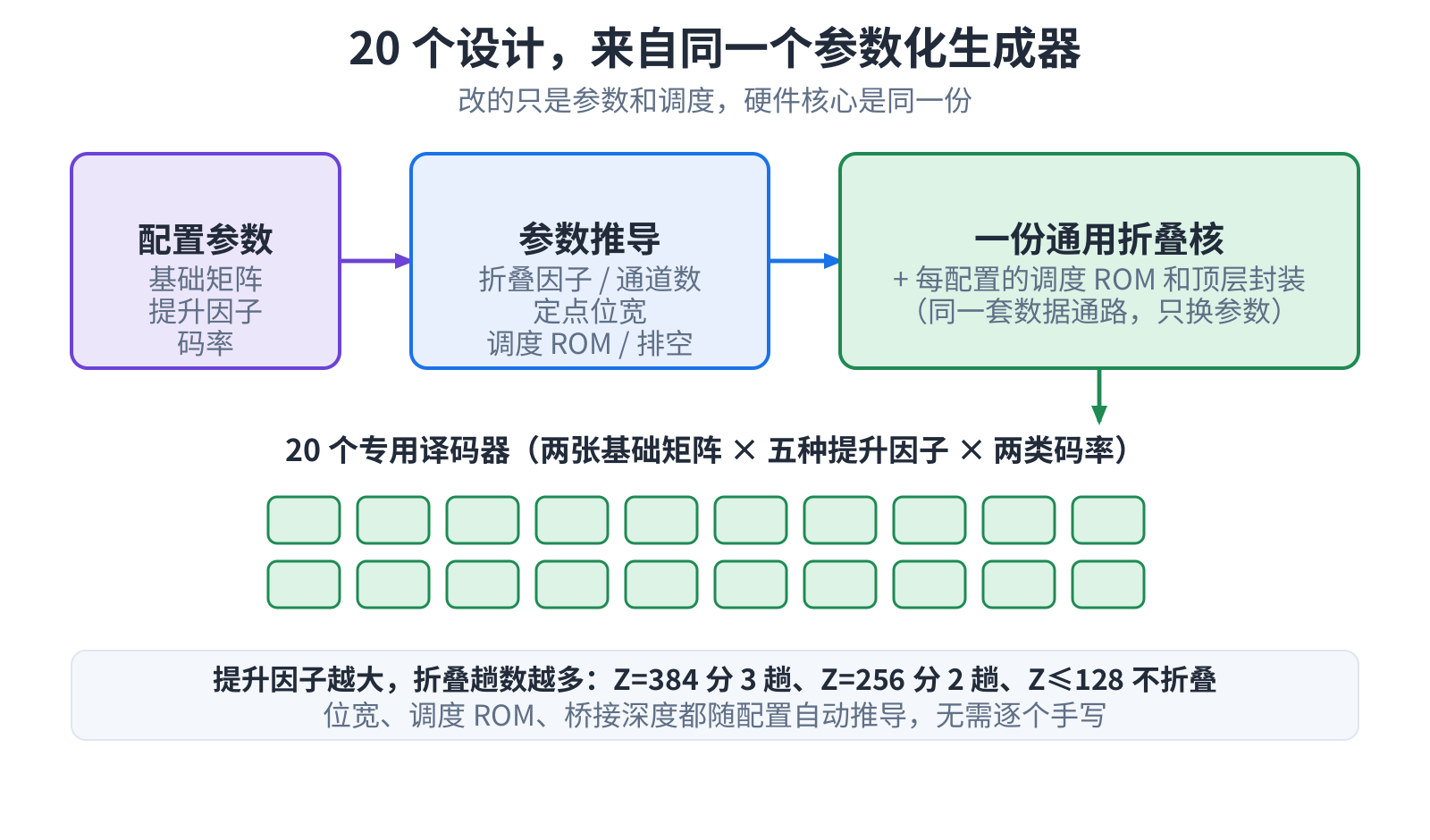
给它一份配置(基矩阵、提升因子、码率),生成器自己推导该折几趟、定点数留几位、调度表怎么排、层与层之间要空几拍, 吐出一颗专用译码器。提升因子越大折得越多,尺寸更小时数据通路本身也跟着收窄。这些都不用人去拍。二十种配置,二十次 换参数,仅此而已。
批量最怕的,是批量造错
生成得快是一回事,生成得对是另一回事。一个能飞快产出、产出却全是错的工具,比没有还糟,所以每一颗都得先证明它对。 这里有三层模型,一层比一层接近硬件:标准算法的数学参考、逐拍精确的周期模型,最后才是综合进 FPGA 的电路。规矩很死: 任何改动,都先改周期模型、再逐位验证、最后才重新生成电路。周期模型是硬件真值参考——模型错了,下游电路再快,也只是 把错误算得更快。
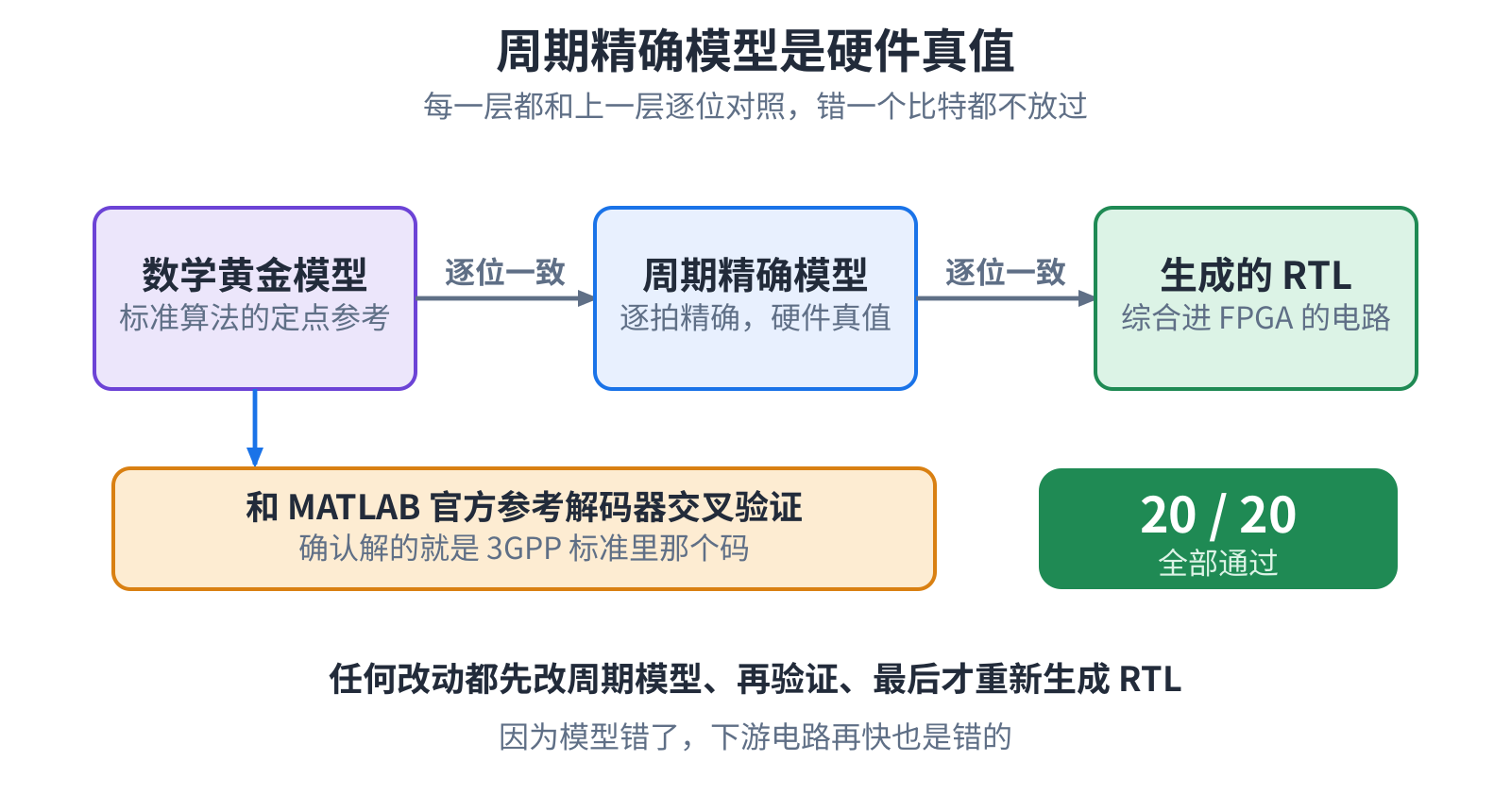
二十种配置,每一颗生成的译码器都和 MATLAB 5G 工具箱里的 3GPP 参考逐位对得上。
收敛也交给工具:一个会回退的闭环
设计生成、验证之后,还得把时序收敛掉。上一篇那几刀,是 AI 一刀一刀试出来的。这一篇,把那身手艺攒成一个闭环,让 工具对二十种配置自己去试。对每一颗设计,它先二分搜出目标时钟该定多紧,然后反复迭代:测量——同一设计跑多条布局 策略取中位数,单跑一次的数字有抖动,信不得;定位——拎出最慢的那条路;选方法——从方法库里照路径类型挑;应用 + 验证——改约束、改参数,或往长路中间插一级寄存器,改完先过逐位比对和吞吐测试;裁决——变快了就接受,过不了就回退, 并把这条死路记下来,下次不再撞。
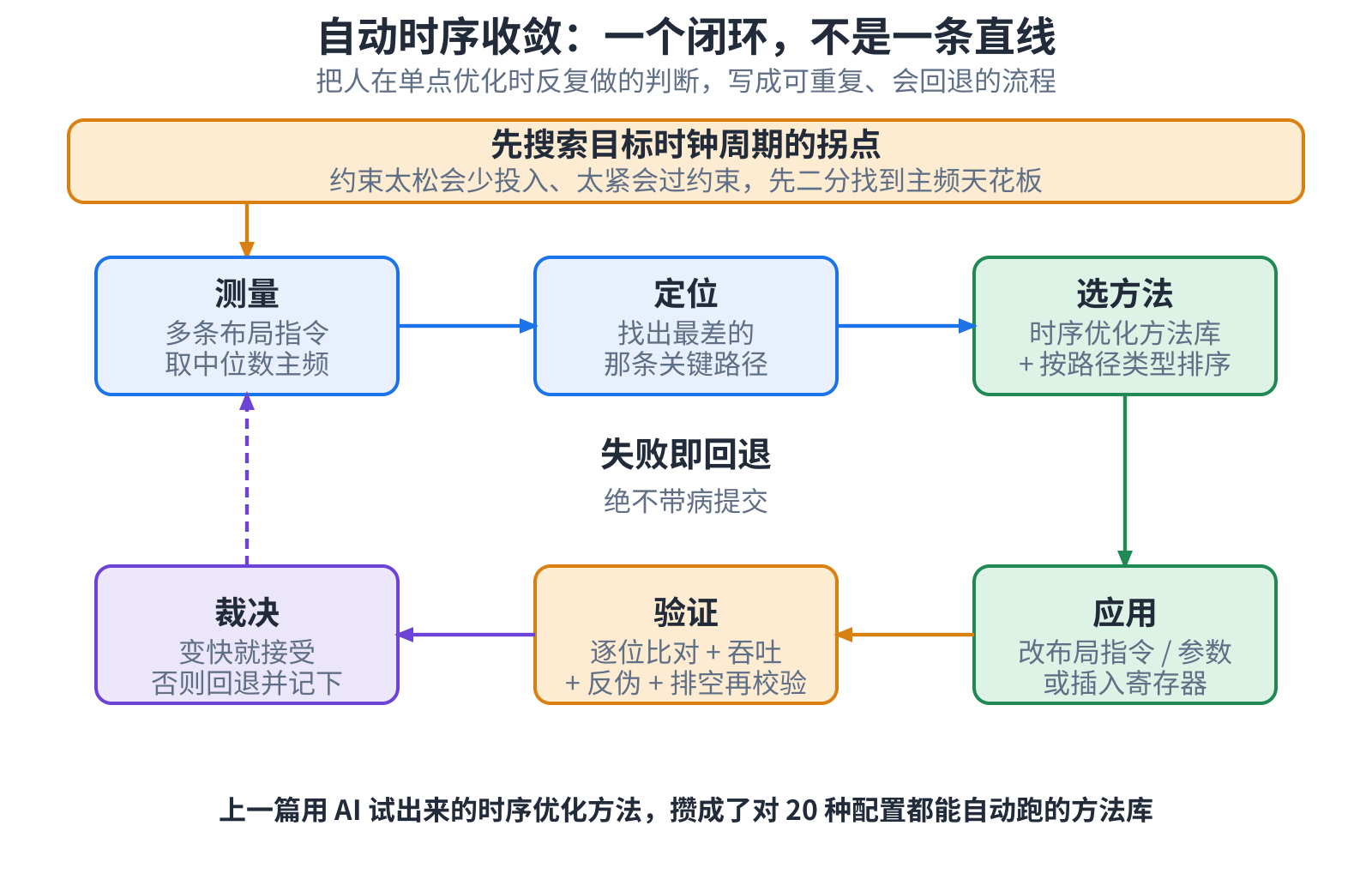
这套闭环最要紧的,是它会回退。宁可报”这个点没收敛”,也绝不把一个没验证过的结果当成功交出去。
结果:时钟追平,吞吐接近
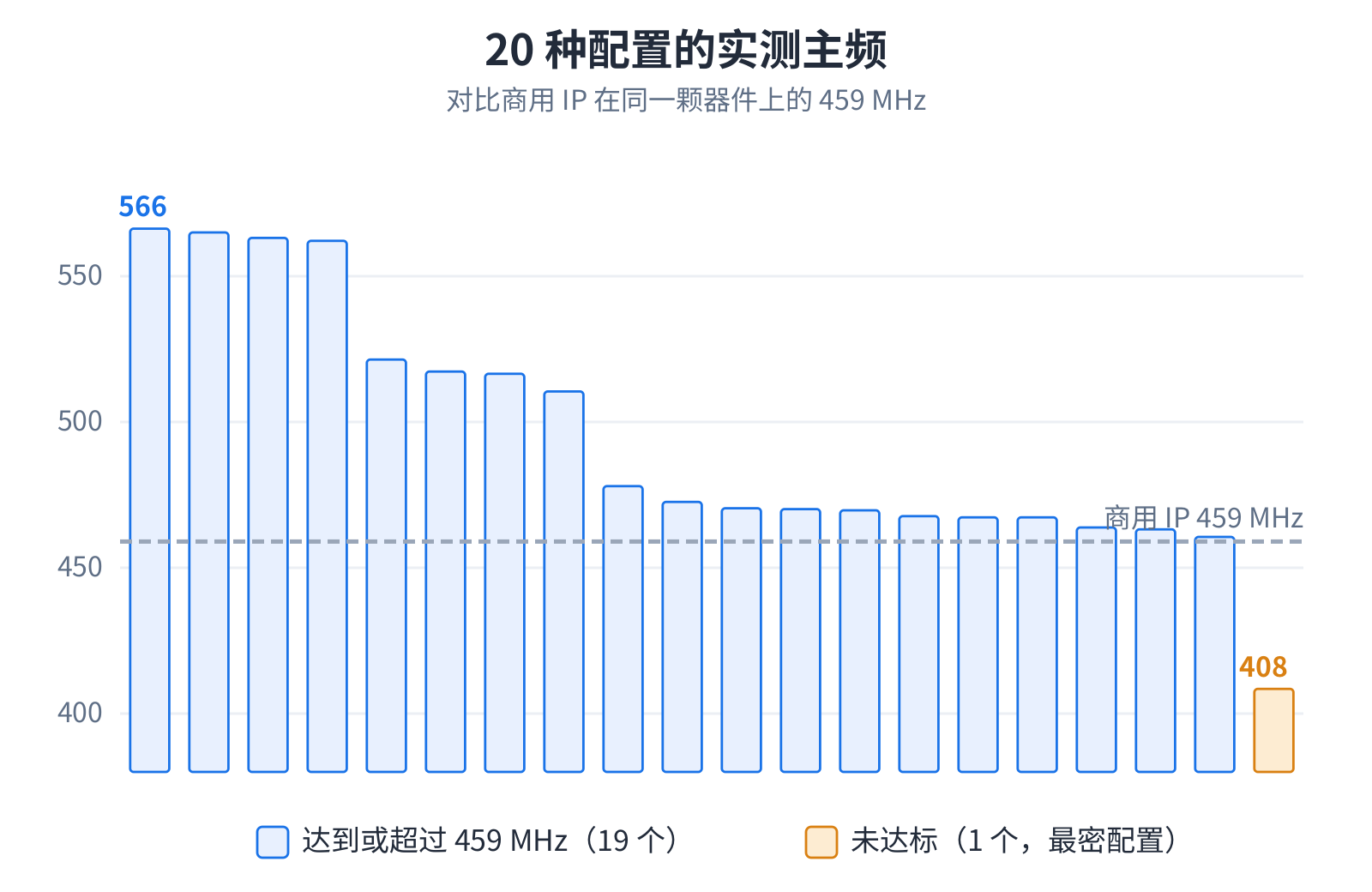
工具一口气把二十种配置全生成、全验证、全收敛,器件还是商用 IP 标称的那颗 FPGA,同一个速度档。二十个里有十九个, 时钟追平或超过了商用 IP 的 459 MHz,中位数略高于它,最快的远远过线。唯一没过线的,是最密的那个配置,被布线拥塞 卡住,工具照实报了出来,没藏着掖着。
吞吐量,老实说
吞吐量得拆开说。架构是同一套,照理能做到接近;实测的差距,差在两边各自用的吞吐技巧上。用实测主频加上提前停止来算, 二十个里大多数超过商用 IP——但这份领先,靠的是更高的时钟,加上信噪比好时迭代提前终止,不是架构赢了。把时钟和迭代 都拉到一样、一个码块对一个码块地比,又轮到它领先。
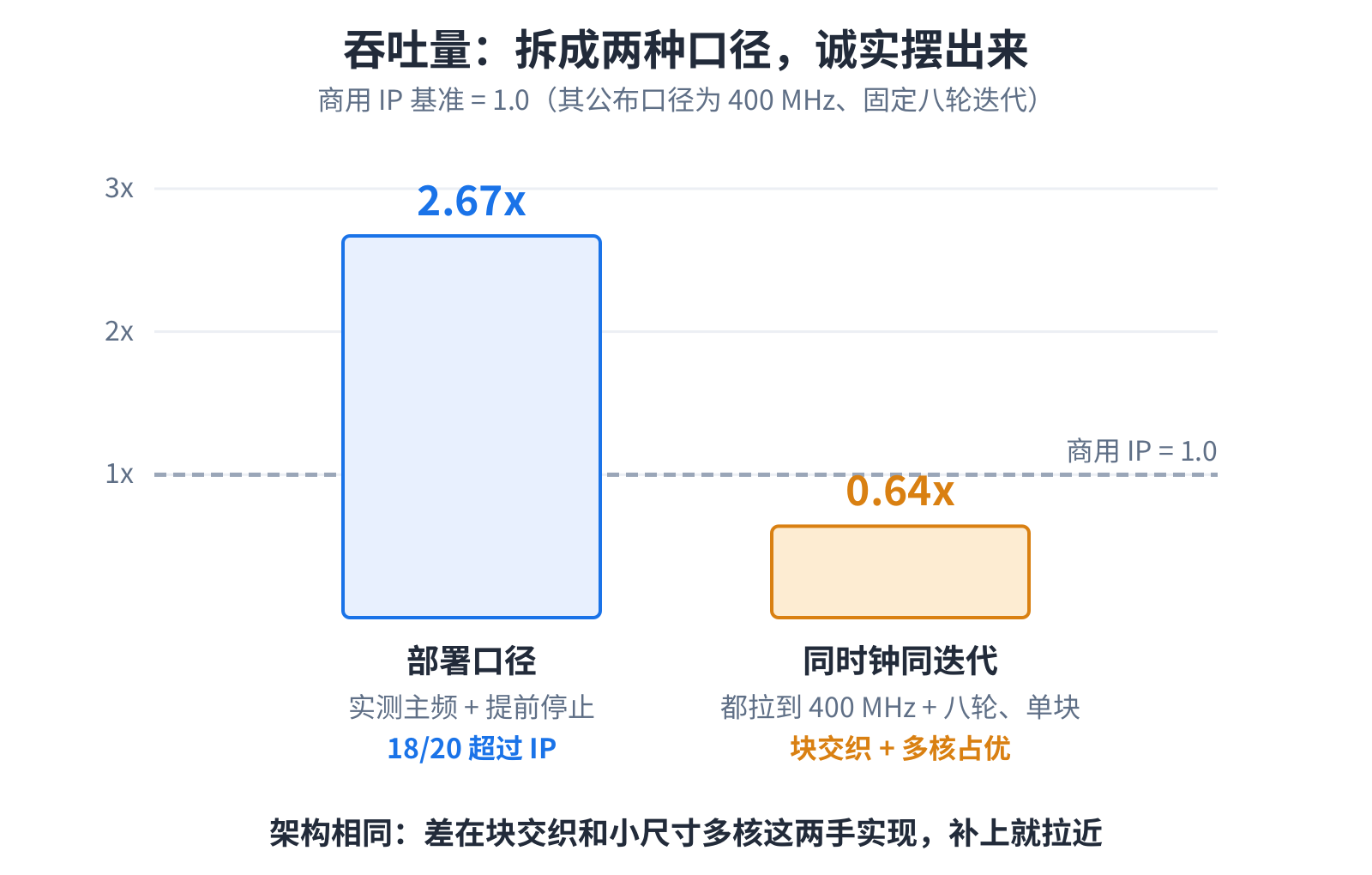
差在两手这版没用上的吞吐技巧:一是块交织,商用 IP 同时解好几个码块、层层交错着喂,用一个码块的计算把另一个的等待 填上;二是小尺寸下的多校验核,提升因子一小那条宽流水线就用不满,商用 IP 并排塞好几个核把宽度填上。两招都不是补不上, 是这一版没上;这一版把本钱压在了早停和更高的时钟上。
杠杆在工具,不在单点
上一篇,用 AI 把一颗设计调过了商用 IP。这一篇,用 AI 做一条流程,把二十颗设计自动生成、自动收敛、逐位验证。后者 才是 AI 在硬件设计里真正会复利的地方。单点加速的价值是线性的,调一个赚一个;工具化的价值是放大的:同一个生成器、 同一张验证网、同一个收敛闭环,覆盖的配置越多,每一个的边际成本越低。

二十个 5G LDPC 译码器,一条流程,十九个的时钟追平或超过那颗付费 IP,每一个都逐位对得上官方参考。这不是哪一颗 设计的胜利,是那个自动把它们全做出来的工具的胜利。