Viterbi 译码器是几乎每条 Wi-Fi、LTE、卫星链路里都有的前向纠错。难的不是译码本身,而是怎么把它 塞进一颗便宜的小 FPGA,或者在一颗芯片上多放几路。说到底,这是个省资源的问题:省查找表、省触发器、 省片上内存。
这个译码器的硬件不是手写的,是用我们的生成框架从 Python 算法代码生成出来的。这篇讲的是接下来的 事:把它交给 AI 去优化资源。AI 做的事跟一个 FPGA 工程师一样,读布局布线后的资源利用率和时序分析 报告,判断省在哪、有哪些方法能省到,量每一个结果,分对错,撞死路就退回来,每改一步都逐比特验证。 真正能复用的不是这一个译码器,是这套循环。
Viterbi 译码器在做什么
先把它讲清楚,不然后面省的是什么、难在哪都说不清。
可以把它想成一张分层的路网图:每一层有几个路口,要找一条从头到尾、总开销最小的路。每个路口只保留 “到这里最划算的那条进路”,其余的扔掉。走到终点,再顺着保留下来的路倒着走回去,最优路径就出来了。 Viterbi 就是这么做的。
放回通信里:卷积码在发送端给每个比特加了冗余,接收端收到的是一串带噪声的软采样。译码器要从这串 噪声里,反推出最可能被发出去的那串比特,这叫最大似然译码。
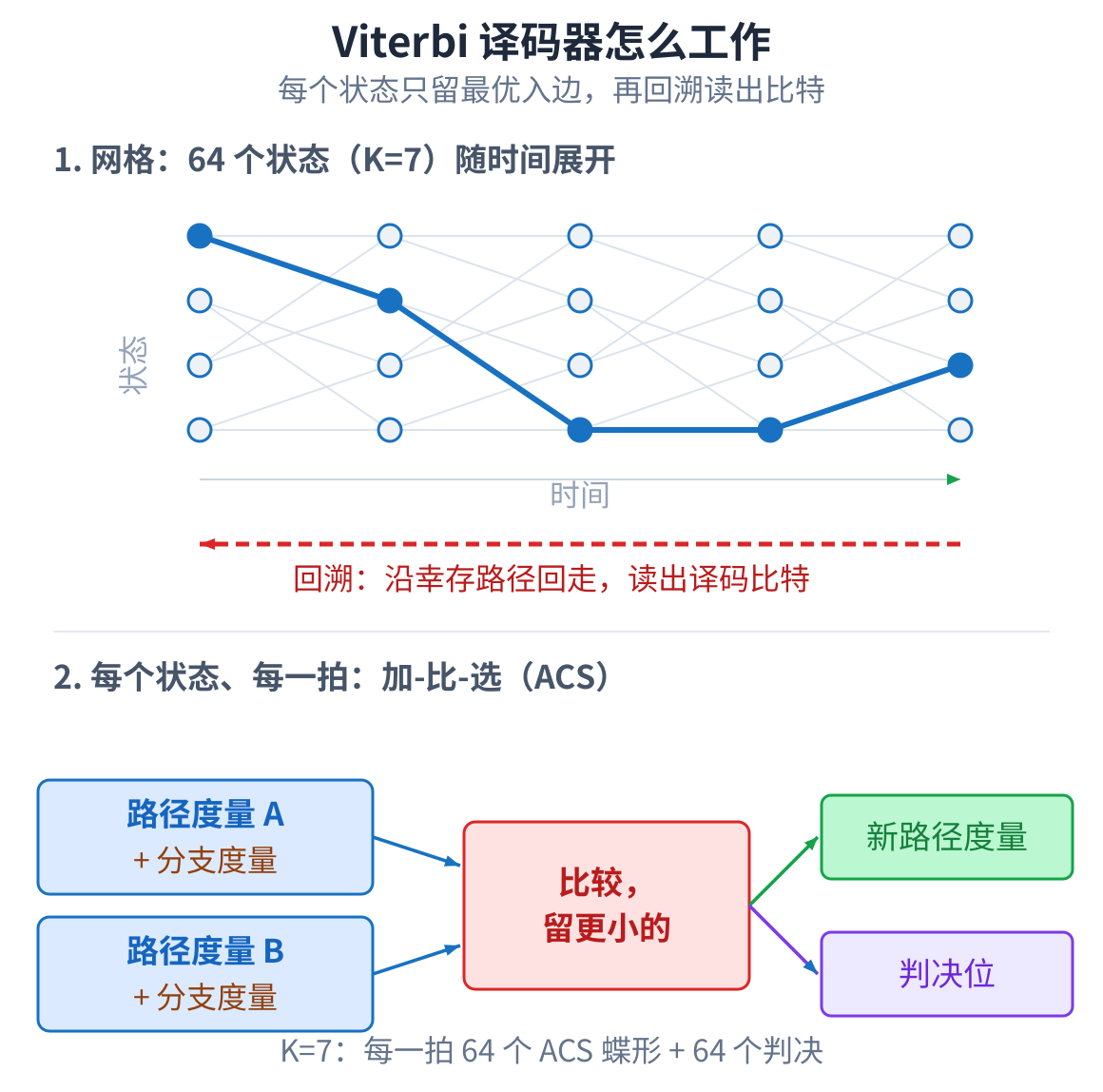
那张路网图叫网格(trellis)。约束长度 K=7,就是 64 个状态、64 个路口。每一拍,每个状态都做一次 加-比-选:加上分支度量,比较两条汇入的路径,留下更优的那条,记下选了谁。攒够足够多的判决,从当前 最优状态顺着这些记录往回走一遍,就把比特一个个译出来,这一步叫回溯。
省资源难在哪
最直接的做法,是给 64 个状态各配一套加-比-选引擎,64 套并排,一拍算完。又快又简单,但又大又费。 而且大部分时间它在空转,因为应用要的吞吐,远低于 FPGA 能跑的吞吐。
更难的一点在加-比-选本身。新的路径度量要用上一拍刚算出来的那个,这是一个反馈环。反馈环的问题是 没法靠加流水线把慢路径切短:下一拍就要用这一拍的结果,插一级寄存器进去只会让环转得更慢。所以 “折叠能省面积”和”折叠后还守不守得住时钟”是两个问题。难就难在这里。
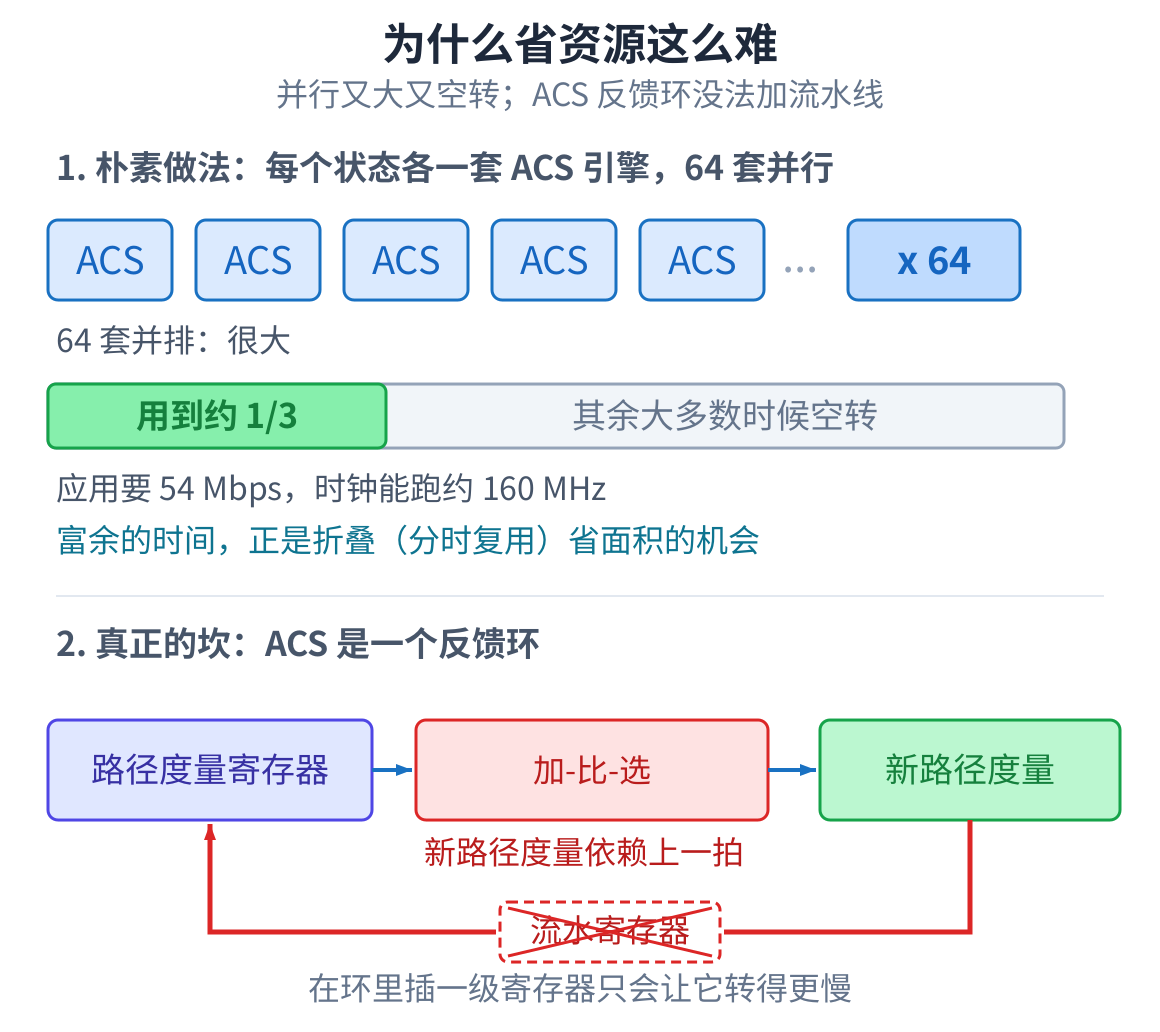
那为什么还要折?因为应用用不上满速。802.11a 最高 54 Mbps,而一个满速译码器在 160 MHz 下每拍出 一个比特,差不多 160 Mbps,比标准要的快了近三倍。宽裕出来的时钟就是机会:把计算分时复用。让一套 引擎跑几拍轮流算完所有状态,而不是铺一大片全并行的硬件。只要吞吐还在 54 Mbps 以上就不亏,省下的 全是面积。剩下唯一的难点,是折的时候别把时钟降下去。
第一个杠杆:折叠
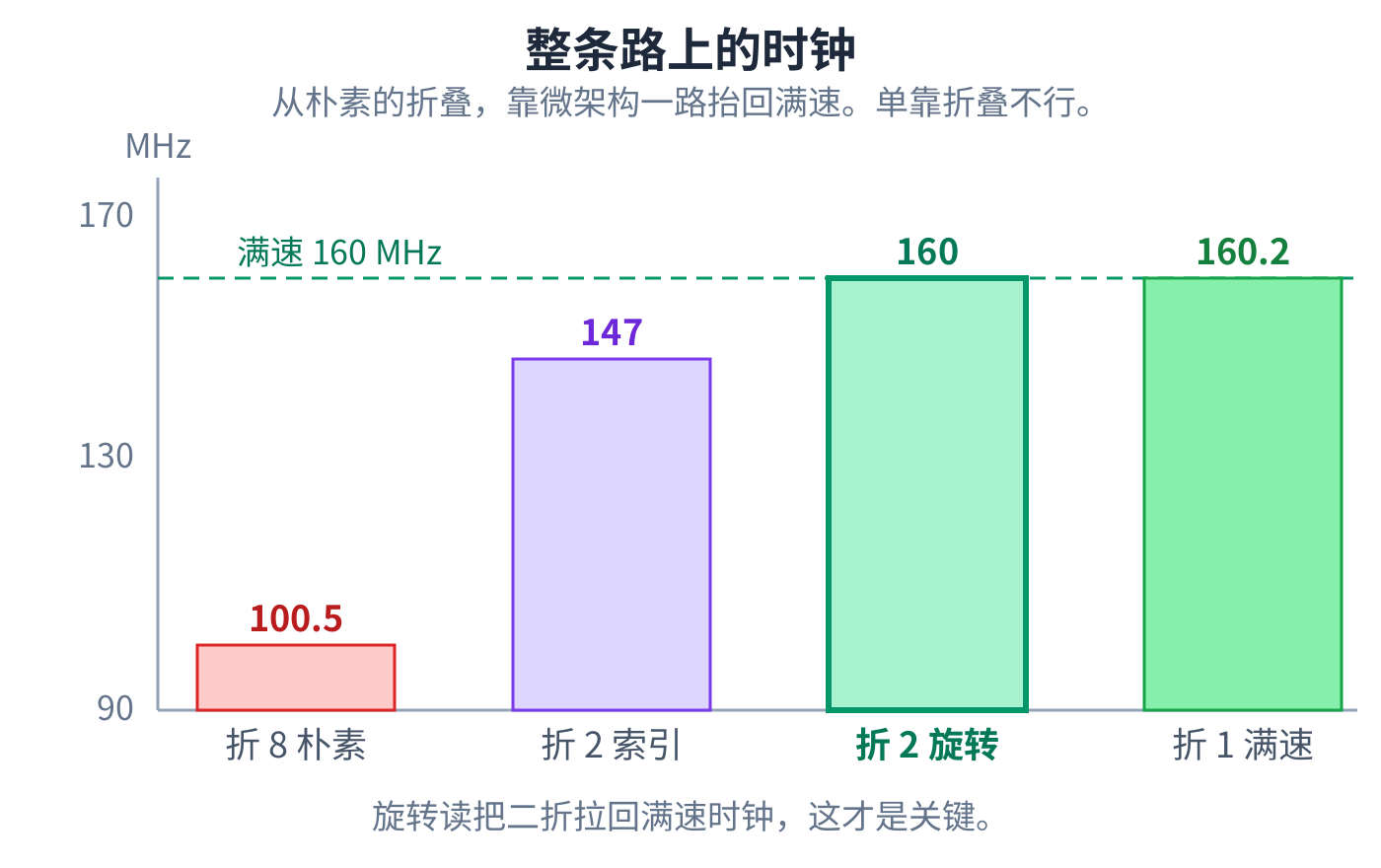
折叠就是把一套加-比-选引擎分几拍轮流复用,而不是给每个状态各造一套。AI 一折,面积就降下来:K=7 的核从大约 2,300 个查找表降到 740 上下,省了接近三分之二。
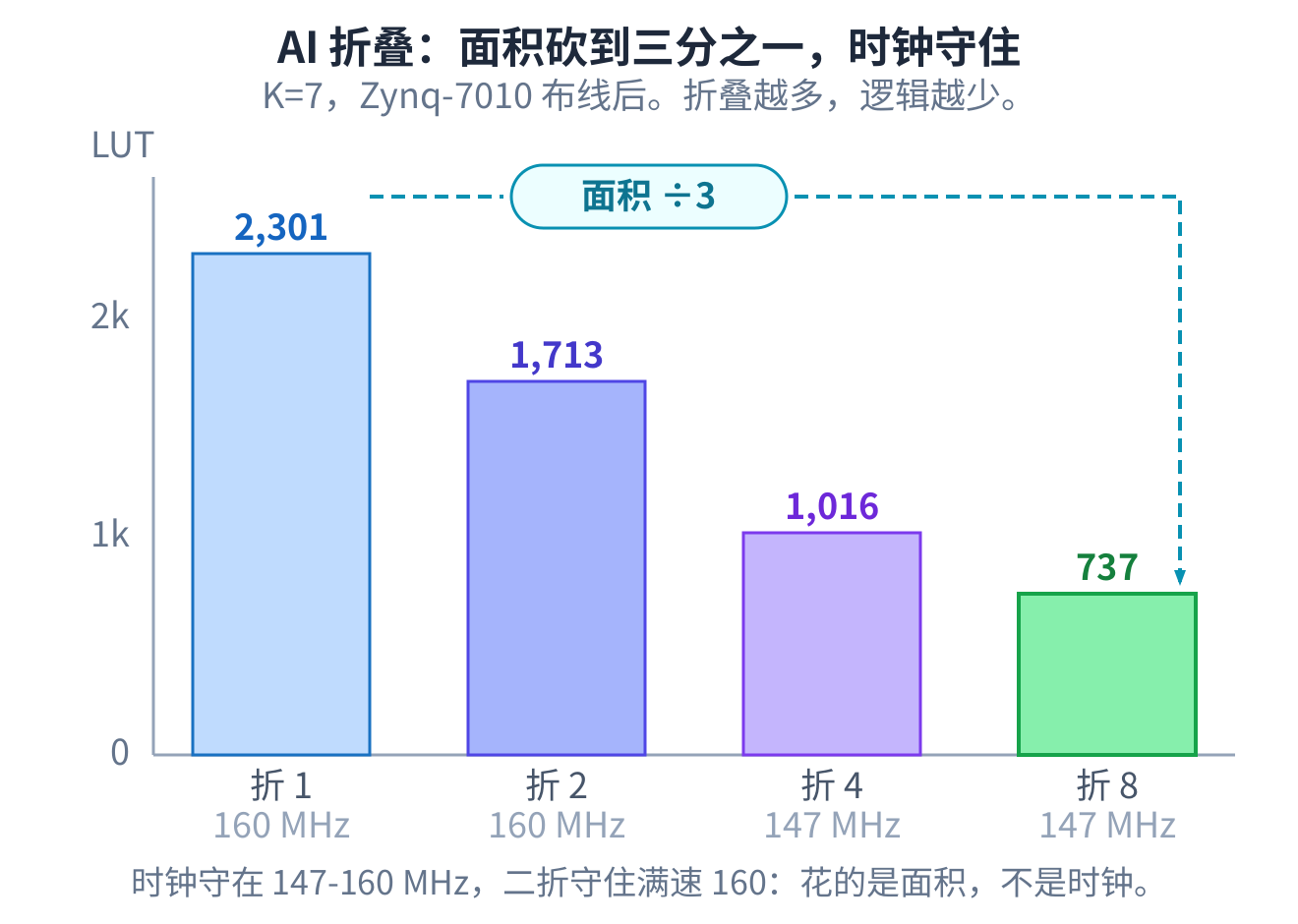
但 AI 量了一下时钟,掉了。它没有停在这里。
诊断:折叠不等于掉时钟
AI 翻到关键路径,原因跟折叠本身关系不大,是读取的微架构没搭对。折叠之后,每拍要读存储 bank 里 不同的一片,最直接的写法是用相位计数器去索引一个多路选择器。问题是这个相位计数器正好压在通往 反馈环的读取路径上,而那条路本来就难做快。
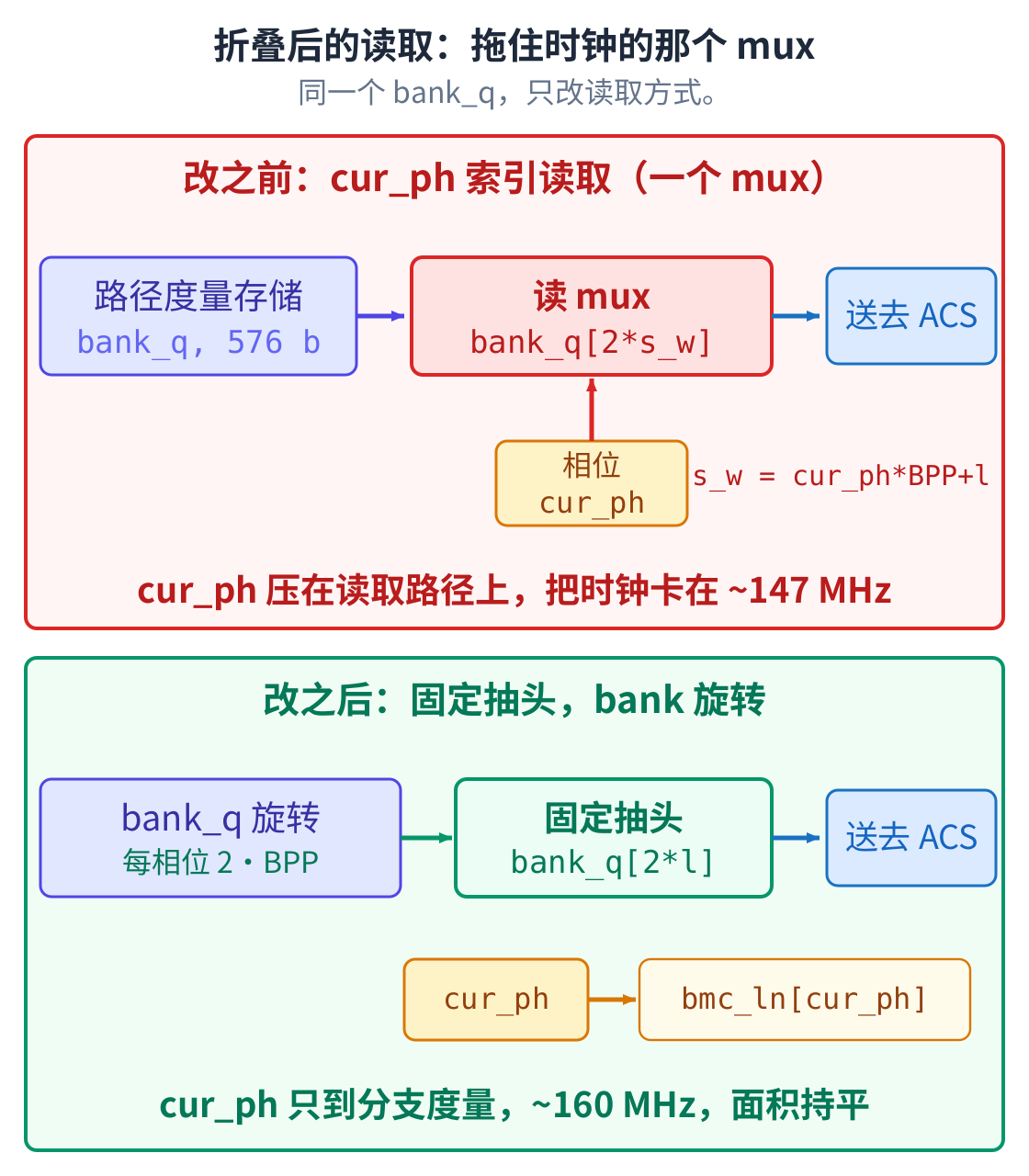
问题不在折叠,在这个读取怎么搭。换个搭法,时钟就回来了。
换上对的微架构
AI 把读取改成旋转:读一个固定不动的抽头,让 bank 每个相位自己转一格,把下一片转到面前。这样相位 计数器就从那条很宽的读取路径上撤下来了,只去选分支度量。AI 再量一遍,同样是二折,时钟从 147 提到 约 160 MHz,逻辑面积没变,触发器还少了几个。
背后有一条通用的道理:折叠任何一个二输入蝶形,都会逼出一次数据重排,躲不掉。能选的只是在哪里 为它买单,这里把它放在了不额外花成本的地方。
还动了几个杠杆
把折叠做高效不是靠一招,而是 AI 一路试出来的一串微架构选择:
- 把共享的大分支度量选择器拆成每路一个,扇出降下来,最深的折叠在最重的码率下把时钟提了两成多。
- 把挡在反馈环前面的加法树挪出去,深码率回到满速。
- 低码率下收窄运算位宽,比折叠更省面积,还顺带把时钟抬高。

撞过一次死路
AI 还试过第三种方案:双缓冲乒乓。做出来、综合、布局布线都跑了一遍,不是只在纸上说。结果是退步, 比旋转读取慢了大约 12 MHz。于是 AI 退了回去。
这个负面结果不浪费。正是它让最后的数字可信:选定的设计是赢过一个真量过、又被否掉的对手,而不是 赢过一个稻草人。
一份资源菜单,用在真正的接收机里
AI 产出的不是一个点,是一份菜单:折得越浅越快越大,折得越深越小越慢。802.11a 要的 54 Mbps,折 1、 折 2 都够;折 4、折 8 更小更慢,留给慢速信道,一颗芯片上能多放几路。每个点都验证过、能交付。
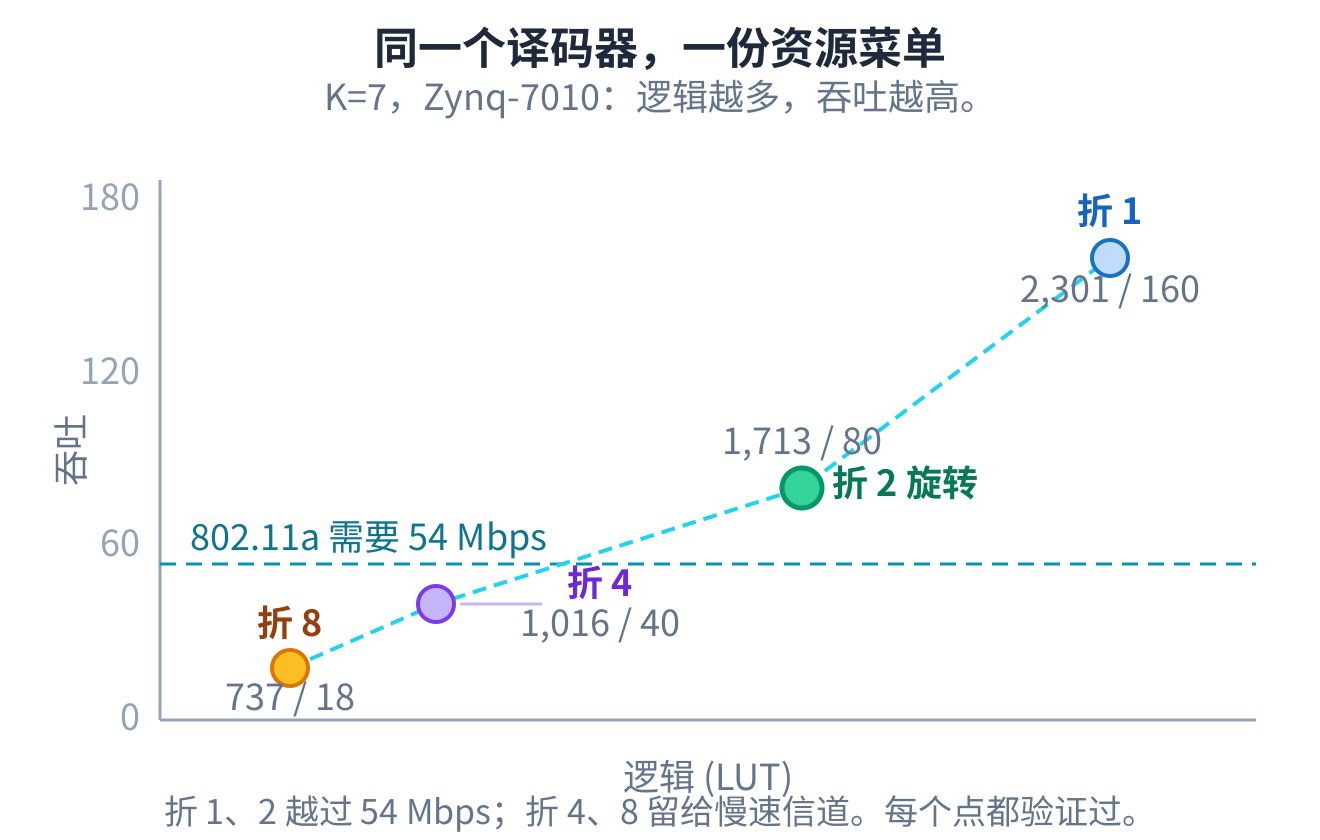
部署用的是二折旋转读取版,放进了一个完整的 802.11a 接收机,喂原始采样,八种调制编码方式全部 零比特错误恢复出载荷。一个在基准上赢的微架构,还得真放进接收机、译真实采样、八种方式零误码, 才算数。
这套循环
最后落地的配置很小也很实在:一个二折译码器守住了满速引擎的时钟,只占折叠引擎的面积,跑在一颗 低成本的 Zynq-7010 上。比这个译码器更有用的,是背后这套循环。
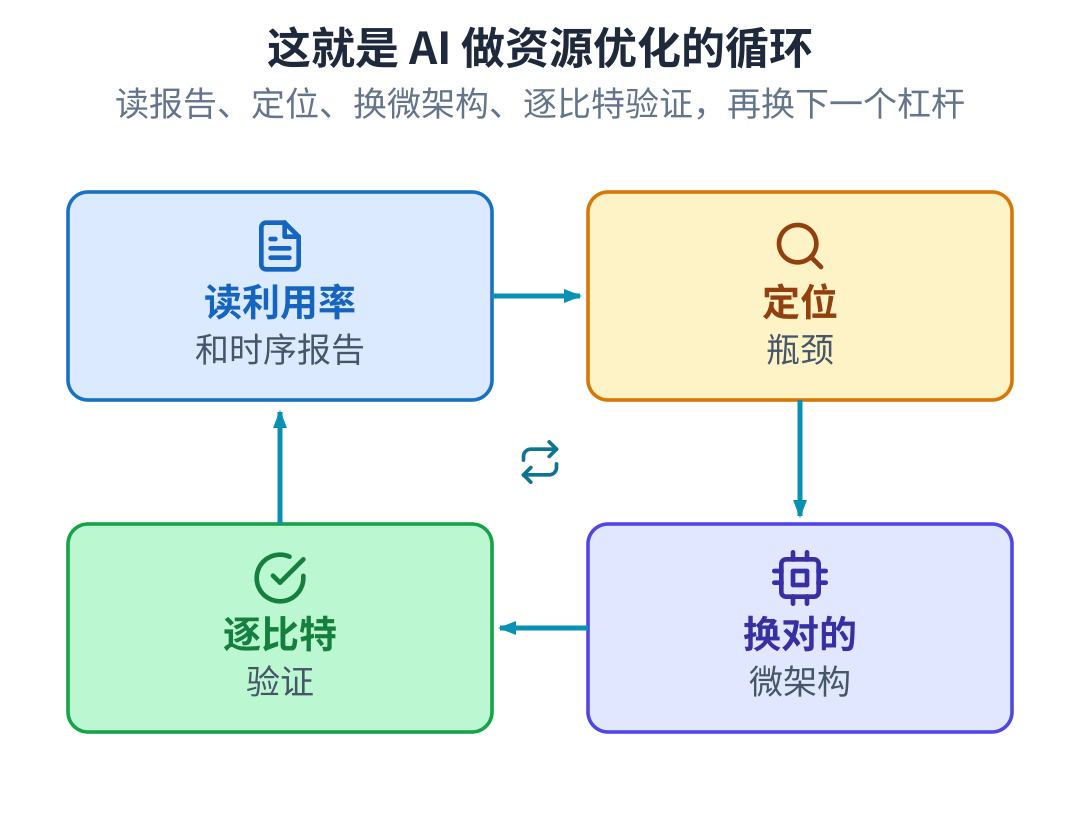
读懂物理约束,分清掉时钟是折叠的问题还是微架构的问题。判断对错:折叠不等于掉时钟,把躲不掉的 重排放到不花成本的地方。撞死路就退:双缓冲量过、退过,负面结果才让数字立得住。逐比特验证:每改 一步先在模型里做对,再翻成硬件,再验一遍。
译码器是可以替换的,这套循环才是值得留下来的东西。