一个完整的 802.11a Wi-Fi 接收机,如今跑在一块 ADALM-Pluto 上:一个巴掌就能握住的软件无线电。 你可以给它喂一段真实的空口信号,看着它把发出去的图像一个像素一个像素地重建出来,零误码。
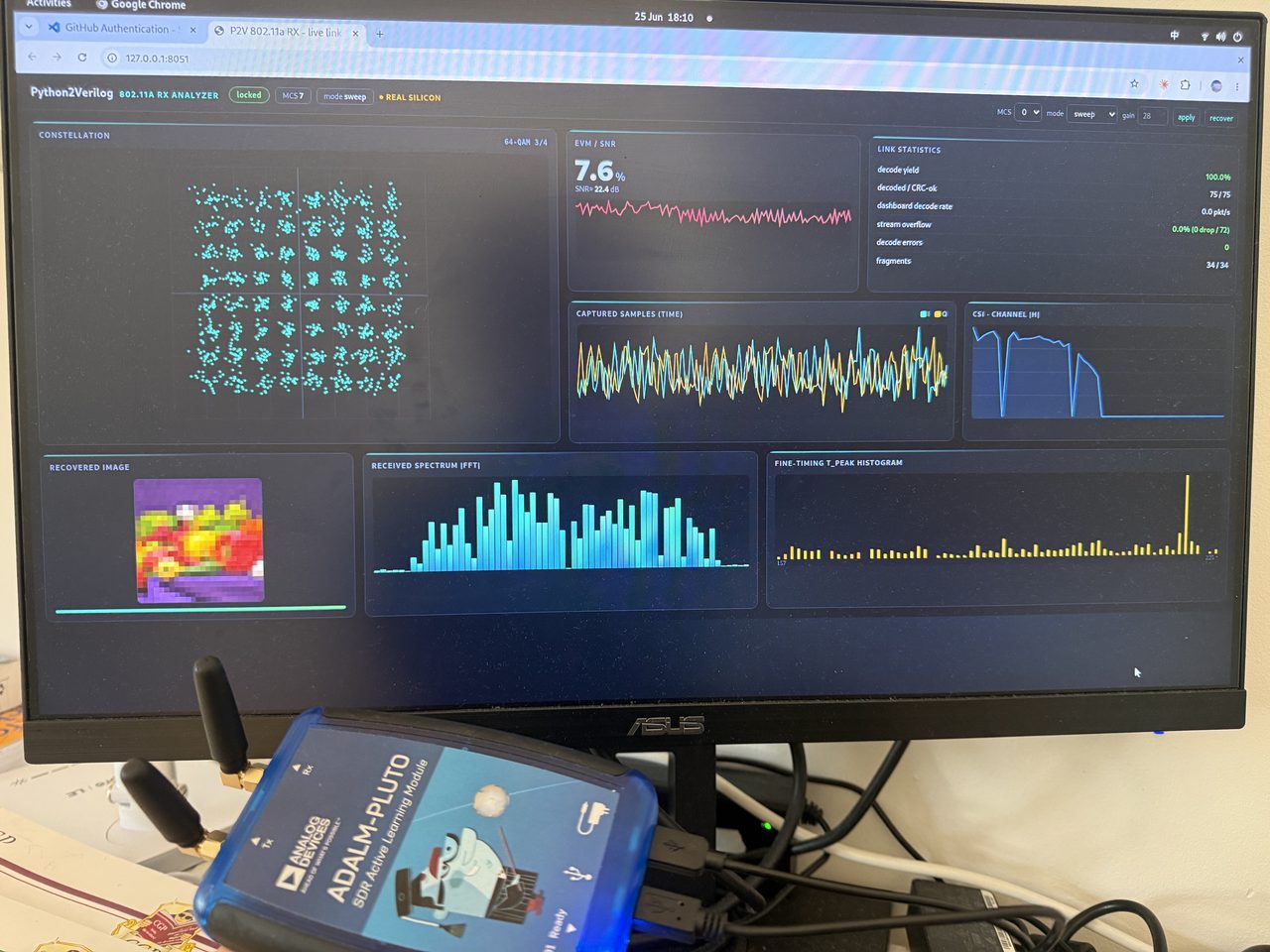
有意思的地方在于:这个接收机其实装不下。完整的设计,加上它必须紧挨着的那套射频接口,比板上 那颗小芯片能容纳的还要大。所以接收机没有做成一整块,而是拆到了两颗处理器上,再用第三颗在中间 搬数据。而这一刀,并没有牺牲唯一真正重要的东西:每一层依然和同一个参考模型逐比特对齐。
它装不下
这块板子用的是 Zynq-7010,它所在系列里最小的型号之一:大约 17,600 个可编程逻辑查找表,别的 不多。
光接收机本身就要用掉其中约 8,500 个。挨着它的那套射频接口,也就是和模拟芯片对话、把采样搬进 搬出的部分,又要再用掉大约 8,500 个。两者一加,还没算别的,就已经超出整颗芯片的预算。做成一 整块的接收机,从一开始就不可能收敛。
这在真实部署里是常态,而不是特例。仿真里能过的设计,放到你真正买得起、要量产的芯片上,往往就 是大了一点,或者慢了一点。问题在于:怎么解决它,又不破坏已经跑通的部分。
把活拆开,但不拆正确性
办法是把接收机切成两半,各自放到该去的地方。
接收机的前段对速率敏感。它要全速看到每一个进来的采样:检测一个数据包何时开始,纠正收发之间的 频率偏差,找到准确的符号定时,再做那个把时域采样变到频域的变换。这部分有一个硬性的实时截止 时间,所以它留在 FPGA 逻辑里,留在电台本体上。
变换之后的一切,就不再受采样时钟约束了。估计信道、把它均衡掉、把软符号判成比特、再跑那个纠正 残余错误的卷积译码器:这些都可以放到一台普通的主机 CPU 上,一台用 USB 连过来的笔记本。电台 自己那颗嵌入式处理器夹在中间,一点运算都不做,它唯一的活就是把采样从逻辑里搬出来,经 USB 送到 主机。
有两件事让这一刀是稳的,而不是冒险的。第一,刀口落在整条流水线最窄的地方。变换之后,数据已经被 压成每个符号几个频点,要过 USB 的东西远比原始采样流少得多;而且只朝一个方向走,从逻辑到主机, 没有任何紧环路绕回来。第二,FPGA 这一半和主机那一半,都和同一个参考模型对过。两者的边界不是一 个允许行为发生漂移的地方:它在两侧都是逐比特一致的,所以拆开后的接收机,算出来的东西和单芯片接 收机分毫不差。
一套流程,换个设计
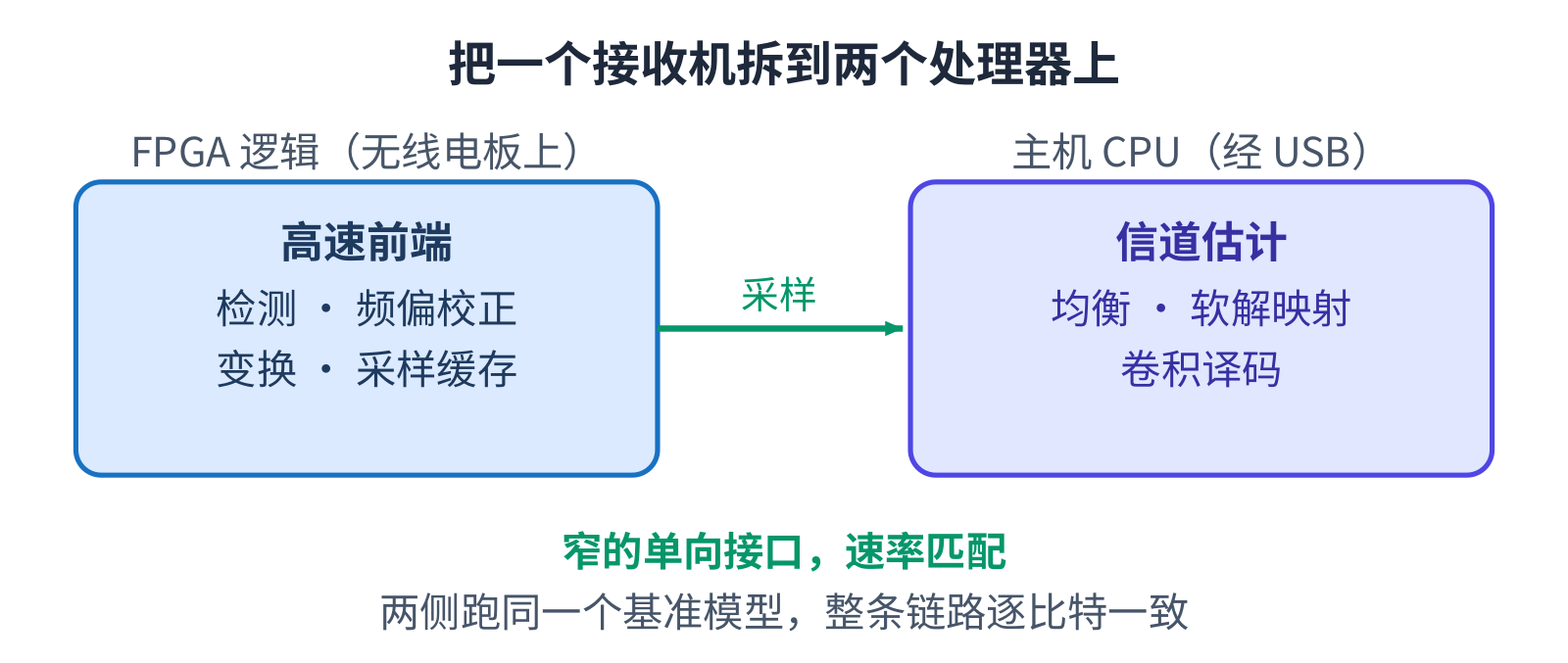
把一个生成出来的模块,用手工拼进厂商的电台设计里,做一次,是一个周末的细致活。要为每一次改动都 重做一遍,项目就卡在这里了。所以部署本身是一条固定的流水线,只有它的输入在变。
一个简短的配置文件描述这个设计。往后的步骤从不改变:生成把模块装进电台现有 FPGA 工程的外壳, 构建比特流,打包固件,烧写板子,再在主机上验证结果。换一个配置,同一条流水线就把另一个设计送上 同一块板子。脚本只写一次;一个新设计是一份新输入,而不是一次新的从头点亮。
一级一级点亮
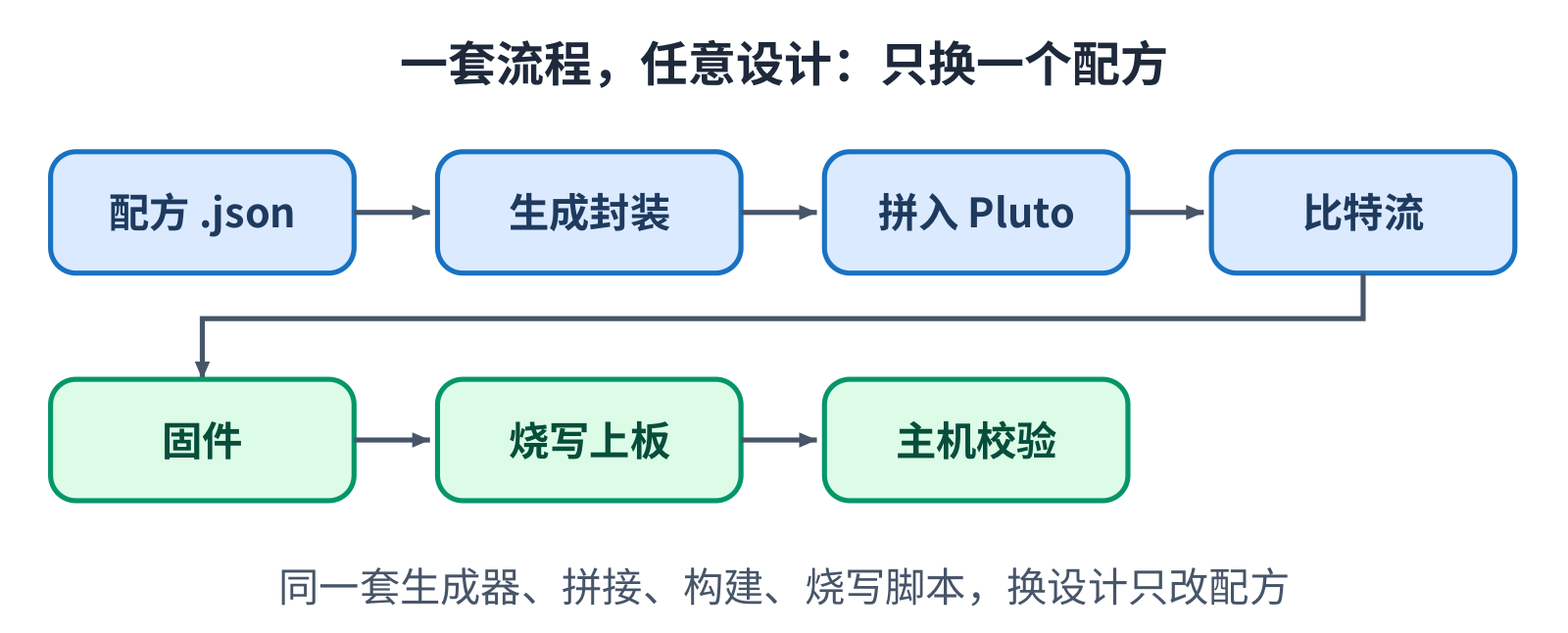
在桌面仿真器里,一个设计要么能跑要么不能,而且你能直接看进它的内部。到了真板子上,几乎什么都看 不见。如果整个接收机一加载,屏幕一片空白,原因可能是工具链、时钟、采样通路、数据搬运,也可能是 接收机逻辑本身,而你没有一个明显的办法分辨是哪一个。
所以没有一次性把所有东西都加载上去。板子是一级一级点亮的,每一级都是一个必须先在真实硬件上通过、 才能尝试下一级的测试。第一级完全不含设计逻辑:它只是读回一段已知的计数斜坡,这就证明了从构建到 烧写到主机读出的整条工具链是好的。第二级加上管路:实时采样抽头、时钟、跨时钟域的交接,接收机仍 然不在。只有这两级都过了,第三级才加载真正的同步加译码设计。
顺序很关键,因为顶上那一级出问题时,在下面几级被证明可靠之前是读不懂的。先花时间把工具链和管路 点亮,那个难缠的 bug 真来的时候,就无处可藏了。
怎么证明
部署上去的前段,在那颗小芯片的逻辑里把时序收敛到了约 162 MHz,比标准要求的速率还留有余量,而且 只占了芯片不到一半的逻辑。剩下的部分,就留给它必须共享这块芯片的射频接口了。
然后是真正的考验:一条实时链路。在标准的全部八种调制编码模式下,从最慢最稳健的,到密集的 64-QAM, 接收机都把负载逐比特地恢复出来。在有线连接上,一次连续运行里它解了 1,390 个数据包,全中,零误码、 零卡死。换成两根天线、一条真正的空口链路,只重新调了一下接收增益,它依然保持 99.88%:832 个里 干净解出 831 个,唯一漏掉的那一个是真实的无线信道事件,而不是设计的缺陷。发出去的图像,完整地回 来了。
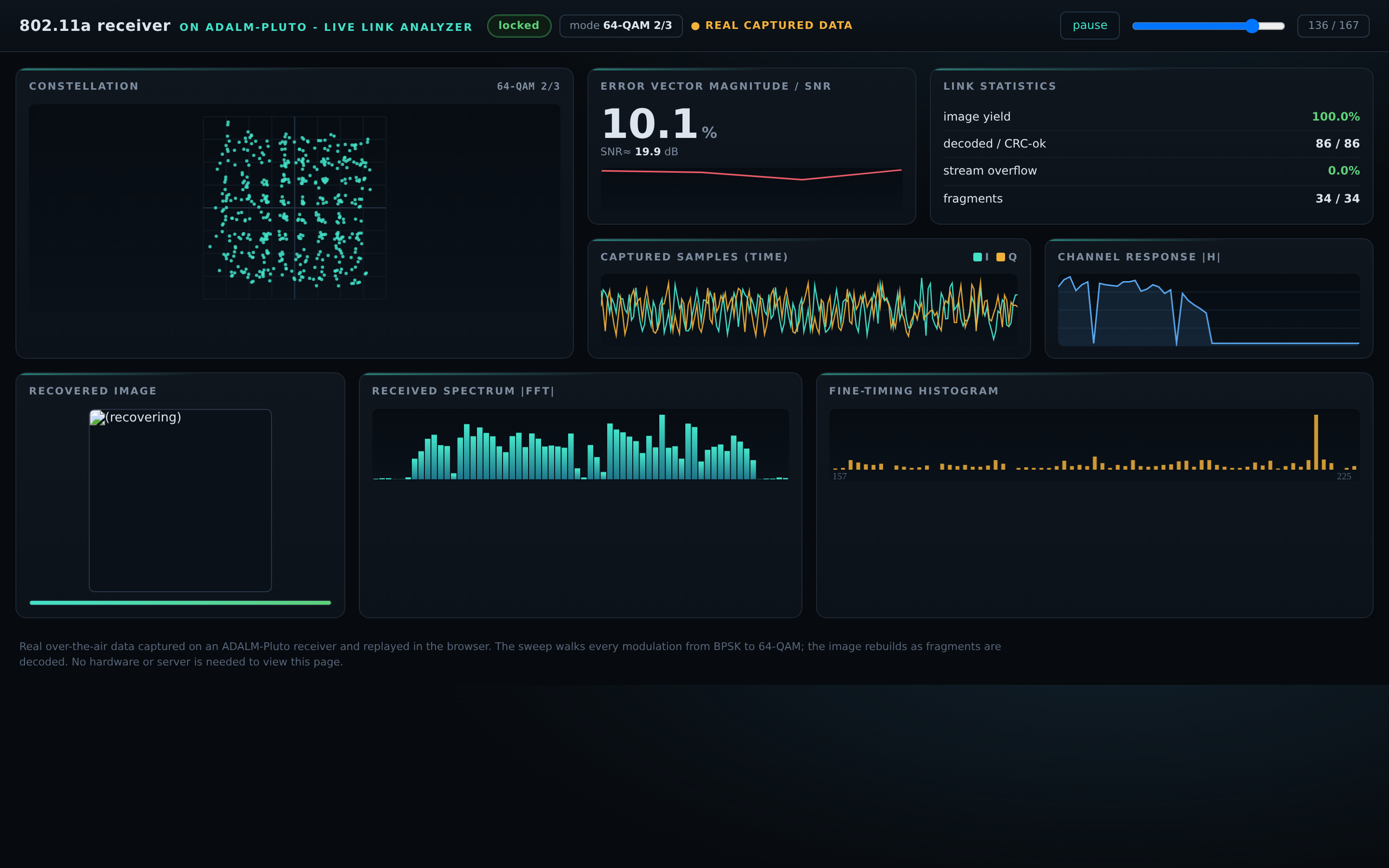
这个面板不是截图。它在你的浏览器里回放真实抓取的数据,随着数据包到达把图像一点点重建出来,不 需要任何硬件、也不用安装。你可以在这里打开它:实时链路分析界面。
为什么可以复用
接收机只是一个设计。可复用的是方法,而且每当一个设计长到一颗芯片装不下时,用的都是同一套方法。
不要为了拆而拆;只在你确实测出了一个天花板时才拆,而且先把每一块就地缩小。真要切的时候,切在最 窄处,让数据单向走,别把紧环路放到边界上,因为一个跨过链路的环路,会把链路的延迟也吃进去。最要紧 的是,让每一块都对齐同一个参考,这样拆开工作量,永远不等于拆开答案。然后在真板子上一级一级地点亮, 让每一级去挣来下一级。
一个在仿真里能过的接收机,是纸面上的结果。同一个接收机,在一块你能握在手里的电台上解着实时信号, 每一种模式都逐比特一致,才是算数的结果。
注记
- 在线演示:空口链路分析界面在浏览器里回放真实抓取的数据,地址 algosilicon.com/assets/demos/wlan-pluto-rx。
- 硬件:ADALM-Pluto,基于 Xilinx Zynq-7010(型号 xc7z010clg225-1)。
- 文中数字为布局布线后的时序与资源数据,以及实测的硬件解码运行结果,均可追溯到该设计当前的工具 报告。
- 另有一篇配套文章,讲这个接收机的硬件是如何被生成、并在上板之前一层一层证明正确的。