A quantum computer is wrong almost all the time. Its bits are so fragile that the only way to get a reliable answer out of an unreliable machine is to spread each logical bit across many physical ones and constantly check them against each other. Every measurement cycle the hardware produces an error signal, and something has to read that signal and work out what most likely went wrong, fast enough that the next cycle does not pile up behind it.
That something is a classical decoder, and it is one of the quiet bottlenecks between the quantum computers we have and the ones we want. For the fast qubits people build today the budget is about a millionth of a second per round, forever. The decoder is not an offline solver you can let think. It is a hard real-time machine.
This is the story of rebuilding one of the best of those decoders, IBM’s Relay-BP, for the code they call the gross code, and learning where its real headroom is.
Three ideas to stop a decoder getting stuck
The standard way to decode this kind of error-correcting code is to let every check and every bit gossip: each tells the others what it believes, everyone updates, and after a few rounds the most likely pattern of errors settles out. On ordinary codes it works beautifully. On quantum codes it gets stuck. The structure of the code creates standoffs where the beliefs just oscillate and never agree.
Relay-BP adds three ideas to break the deadlock.
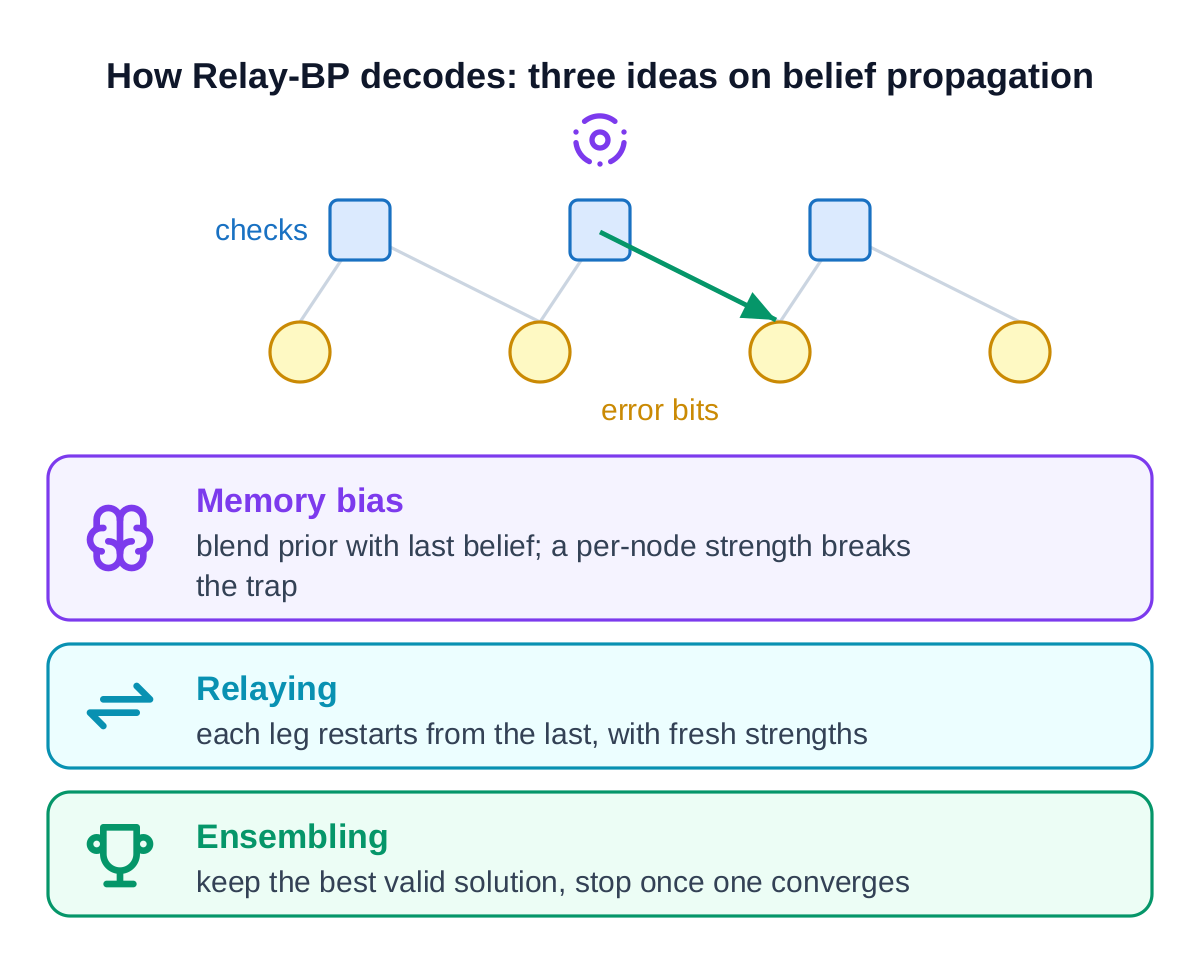
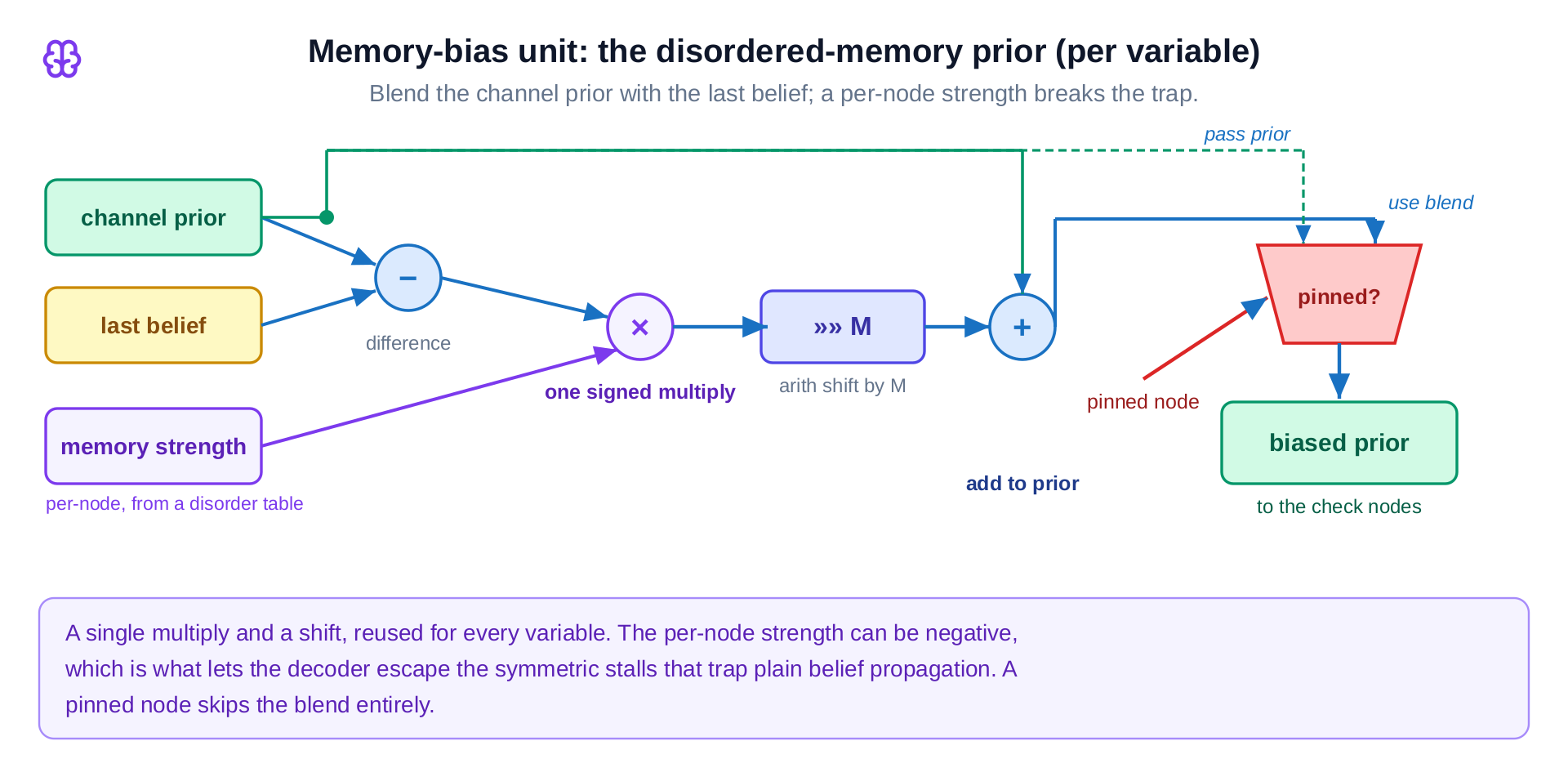
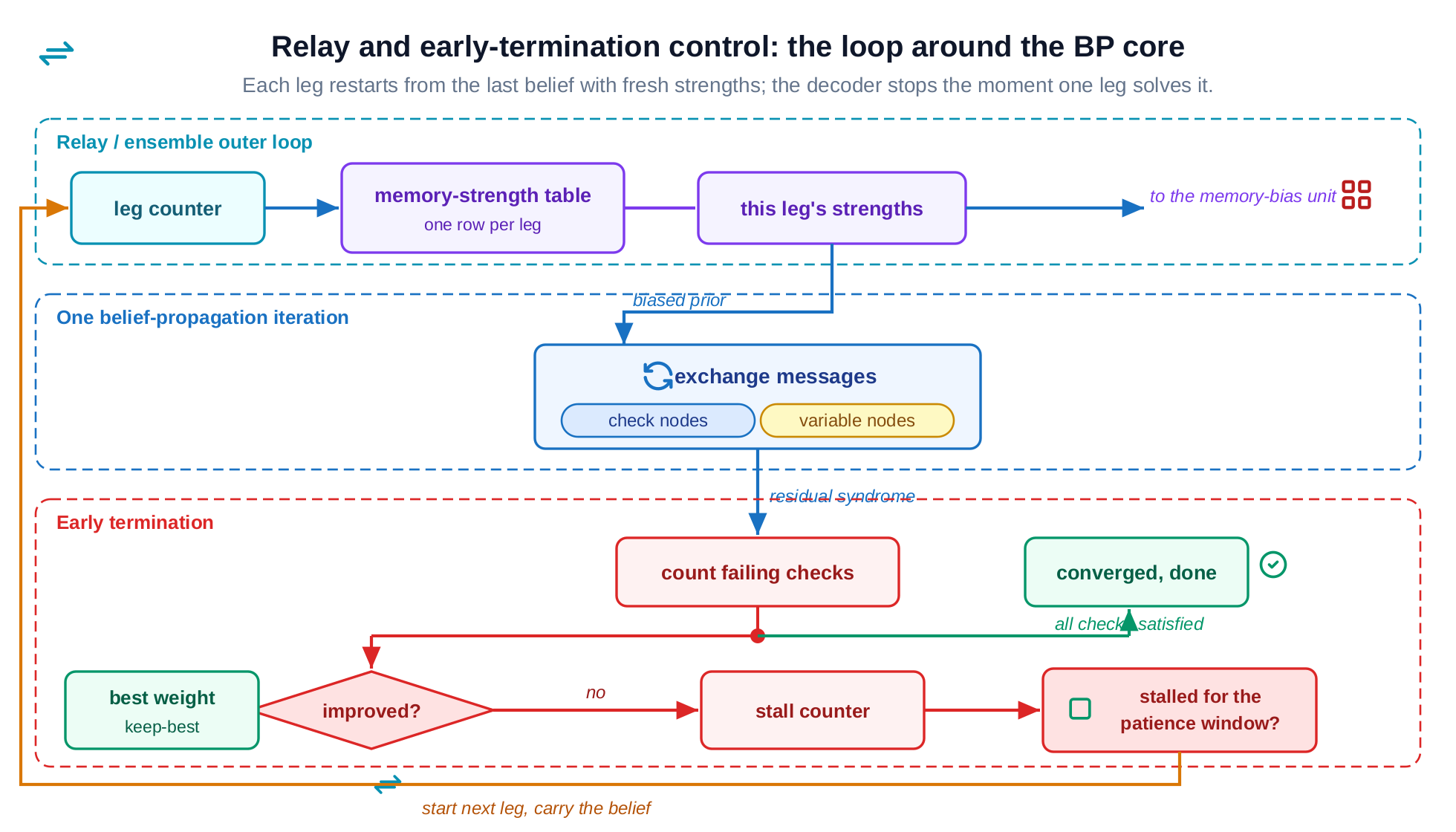
The first gives each bit a small amount of memory, nudging it with its own past belief by an amount that is allowed to push the wrong way. That sounds odd, and it is exactly the trick: a gentle shove off balance is what knocks the decoder out of a standoff. The second runs the whole decode as a relay of several attempts, each starting where the last left off but with the shoves freshly redrawn, like trying a new route to the same destination. The third keeps the best valid answer it has seen and stops the moment one attempt genuinely solves it.
What the machine actually is
We did not adapt anyone’s code. We rebuilt the decoder from the algorithm down to real silicon with our own flow, generating the hardware from a model that is checked against the mathematics at every step, so the chip provably does the same thing as the textbook.
The whole machine turns out to be a few small units repeated across the graph of the code. The memory idea, the one that sounded clever, is almost embarrassingly cheap in hardware: one multiply and a shift, with a way to leave certain bits untouched.
The wall is the wiring, not the maths
To hit the time budget the decoder is laid out fully in parallel: every part of the problem gets its own piece of hardware and they all work at once. There is no central memory the messages pass through; the messages live in the wires between the units.
That choice sets where the speed limit comes from. When we placed and routed the design and looked at what was holding back the clock, most of the delay was not computing anything. It was just carrying messages across the chip. The wiring is the wall, and it is the same wall for anyone who builds this the same way. Our version lands on the same envelope as IBM’s published chip: about the same clock, about the same size. Not faster, because the wall does not move for a re-implementation.

So where is the room?
If the clock is fixed by the wiring, then making the decode finish sooner is not about a faster clock at all. It is about doing fewer attempts. We tried the obvious hardware tricks first, and most of them backfired: a deeper pipeline raised the clock but made each decode take more steps, and squeezing the layout closer together only made the wiring worse.
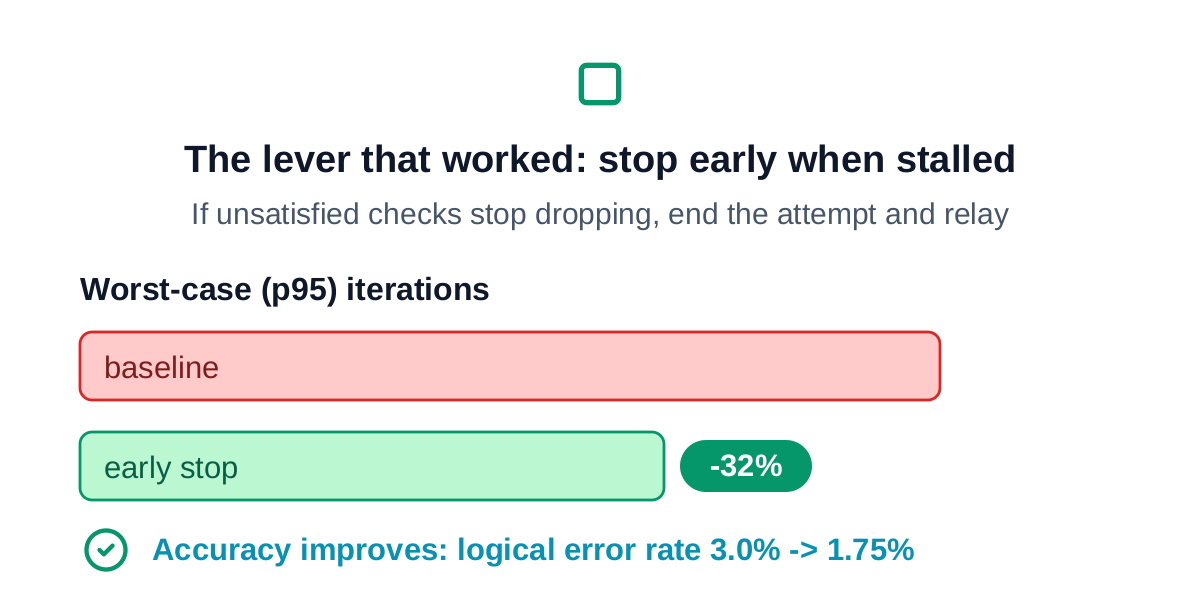
The lever that actually worked is in the algorithm. The control logic already counts how many checks are still failing. If that count stops improving for a while, the attempt is stuck, so stop it and start the next relay. Watching for the stall and bailing out cut the worst-case time to decode by about a third, and the accuracy got slightly better rather than worse, because each fresh attempt explores a new path to a valid answer. In hardware it costs almost nothing: a counter and a comparison.
The honest result
The decoder we built matches the published chip rather than beating it, and the reason is worth keeping: when the speed limit is set by physics you cannot re-route, the win is not in the hardware tricks. It is in asking the machine to do less work. The transferable part is that habit of measuring where the limit really comes from before reaching for a clever fix, and of proving every change does the same thing as the model that came before it. That is the part that carries to the next design, long after this one.