量子计算机几乎时时刻刻都在出错。它的比特太脆弱,想从一台不可靠的机器里得到可靠的答案,唯一的办法 就是把每一个逻辑比特摊到许多物理比特上,不停地让它们互相核对。每一轮测量,硬件都会产生一个错误信号, 得有东西去读这个信号,推断出最可能哪里错了,而且要快到下一轮不会堆积在它后面。
这个东西就是经典译码器,它是横在我们已有的量子计算机与我们想要的量子计算机之间,一个不太被提起的瓶颈。 对今天人们做的快速量子比特来说,预算大约是每轮一百万分之一秒,永远如此。译码器不是一个可以慢慢想的离线 求解器,而是一台硬实时的机器。
这是把其中最好的译码器之一,IBM 的 Relay-BP,为他们称作 gross 码的那个码重新搭一遍,并弄清它真正余量 在哪的故事。
三个想法,让译码器不再卡住
译这类纠错码的常规办法,是让每个校验和每个比特互相通气:各自把自己的判断告诉别人,大家更新,几轮之后 最可能的错误图样就浮现出来。在普通码上它运转得很漂亮,在量子码上却会卡住。码的结构会制造出僵局,让各自 的判断来回振荡、永远谈不拢。
Relay-BP 加了三个想法来打破僵局。
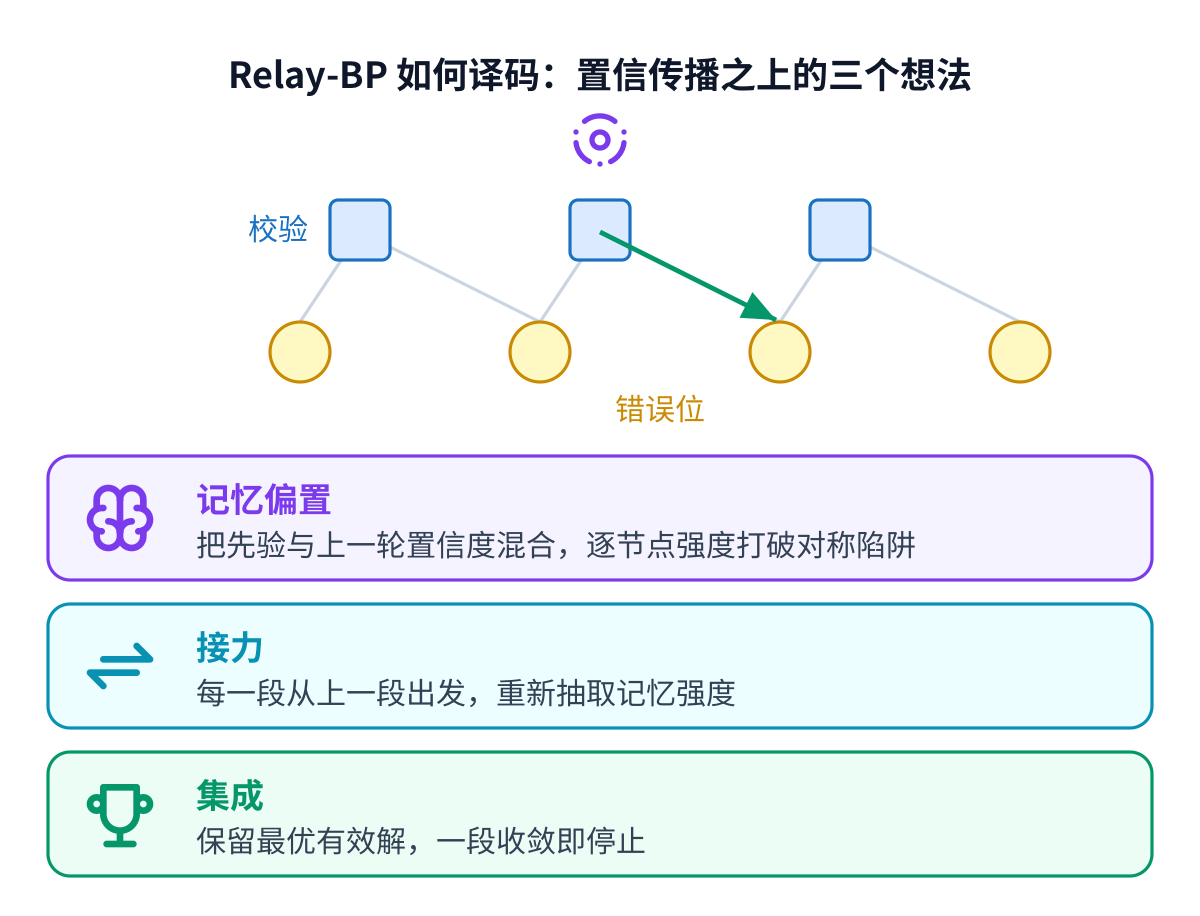
第一个给每个比特一点记忆,用它自己过去的判断去轻推它,而且这一推允许往”错”的方向推。这听起来奇怪, 却正是诀窍:一记轻轻的失衡,恰好能把译码器从僵局里撞出来。第二个把整个译码当成几次尝试的接力,每一次 都从上一次停下的地方出发,但重新抽取那些推力,就像换一条路去同一个目的地。第三个保留它见过的、真正 可行的最优答案,并在某一次尝试真正解出的瞬间停下来。
这台机器到底是什么
我们没有改别人的代码,而是用自己的流程,从算法一路搭到真实硅片,硬件由一个在每一步都与数学核对过的 模型生成出来,所以芯片可以被证明做的就是课本上那件事。
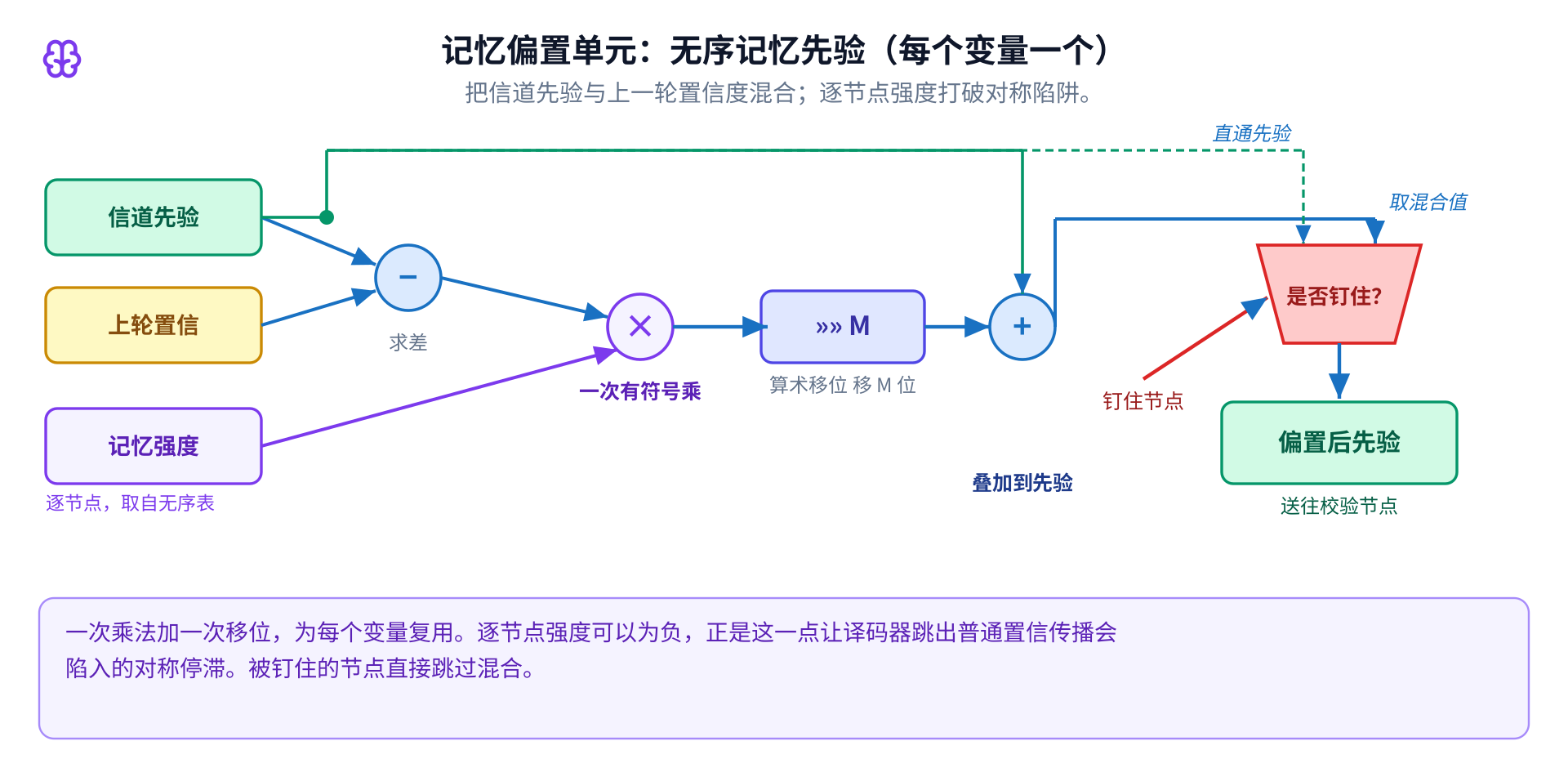
整台机器其实是几个小单元在码的图上反复铺开。那个听上去很巧的记忆想法,在硬件里便宜到近乎不好意思: 一次乘法加一次移位,外加一条让某些比特保持原样的旁路。
那堵墙是布线,不是数学
为了赶上时间预算,译码器被完全并行地铺开:问题的每一部分都有自己的一块硬件,全部同时工作。消息没有 经过一块集中的存储,它们就活在各单元之间的连线里。
这个选择决定了速度上限来自哪里。当我们把设计布局布线、再看是什么在拖住时钟时,大部分延迟根本不是在算 什么,而只是在把消息搬过整片芯片。布线就是那堵墙,对任何用同样方式搭的人都是同一堵墙。我们这一版落在 与 IBM 已发表芯片相同的包络上:差不多的时钟、差不多的规模。没有更快,因为这堵墙不会因为重新实现一遍 而挪动。

那么余量在哪
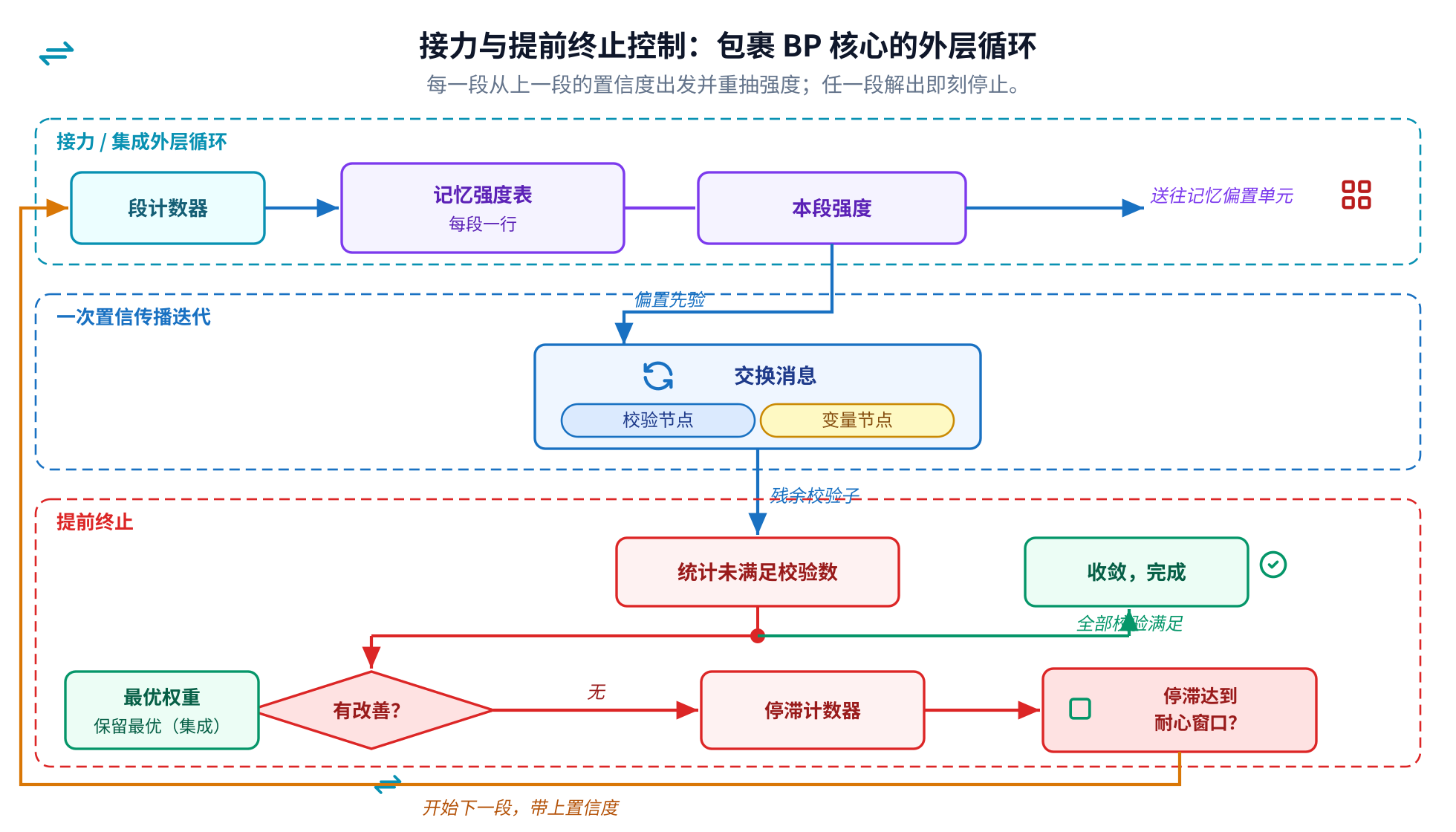
如果时钟被布线钉死了,那么让译码更早完成就根本不在于更快的时钟,而在于做更少的尝试。我们先试了那些 显而易见的硬件招数,大多数反而帮了倒忙:更深的流水提升了时钟,却让每次译码多走几步;把布局挤得更紧, 只让布线更糟。
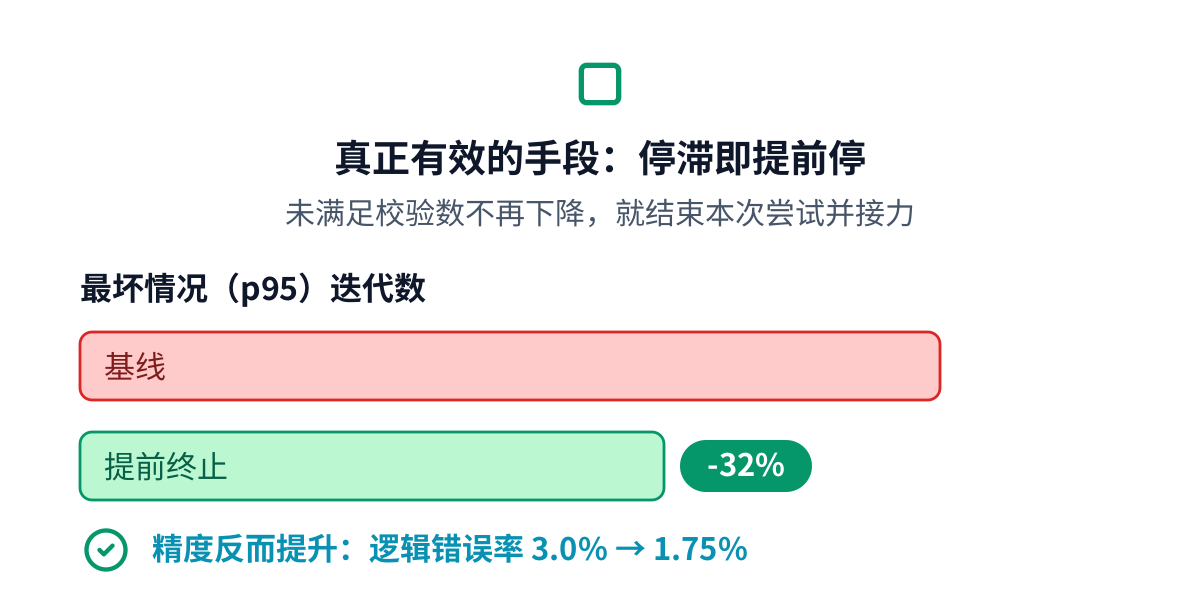
真正有效的杠杆在算法里。控制逻辑本来就在数还有多少校验没被满足。如果这个数在一段时间里不再下降,说明 这次尝试卡住了,那就停掉它,开始下一段接力。盯住这个停滞并及时退出,把最坏情况的译码时间削掉了约三分 之一,而且精度不降反升,因为每一次新的尝试都在探索一条通往可行答案的新路。在硬件上它几乎不花什么: 一个计数器和一次比较。
诚实的结论
我们搭出来的译码器,是追平了已发表的芯片,而不是超过它,而这个原因值得记住:当速度上限由你无法重新布线 的物理决定时,胜负不在硬件招数里,而在于让机器少做一点活。可迁移的那一部分,是先去测清楚上限究竟来自 哪里、再伸手去做巧妙修补的那个习惯,以及证明每一次改动与它之前那个模型做的是同一件事。这一部分会带到 下一个设计里,远在这一个之后。